As Machine Learning (ML) grows, more industries, from healthcare to banking, adopt machine learning models to generate predictions. These predictions are being used to justify the cost of healthcare and for loan approvals or denials. For regulated industries that are adopting machine learning, the interpretability of models is a requirement. In Machine Learning, interpretability can be defined as "the ability to explain or present in understandable terms to a human [being]."[1]
A few of the motivations for interpretability are as follows:
- Better human understanding of impactful technologies
- Regulation compliance and General Data Protection Regulations (GDPRs)
- Check and balance against accidental or intentional discrimination
- Hacking and adversarial attacks
- Alignment with US FTC and OMB guidance on transparency and explainability
- Prevent the building of excessive Technical Debt in Machine Learning
- More in-depth insight and understanding of your data
In this self-paced course, we will build a machine learning model using the famous Default of Credit Card Clients Dataset. We will use the dataset to build a classification model that will predict the probability of clients defaulting on their next credit card payment. In contrast to previous self-paced courses, we will focus on the most leading methods and concepts for explaining and interpreting Machine Learning models. Therefore, we will not focus so much on the experiment itself. Instead, we would shift our attention to using the following metrics and graphs that Driverless AI generates to understand our built model: results, graphs, scores, and reason code values. In particular, we will explore the following graphs in Driverless AI:
- Decision tree surrogate models
- Individual conditional expectation (ICE) plots
- K local interpretable model-agnostic explanations (K-LIME)
- Leave-one-covariate-out (LOCO) local feature importance
- Partial dependence plots
- Random forest feature importance
Before we explore these techniques in detail, we will briefly introduce ourselves to the following fundamental concepts in machine learning interpretability (MLI):
- Machine Learning Interpretability Taxonomy
- Response Function Complexity
- Linear, monotonic functions
- Nonlinear, monotonic functions
- Nonlinear, non-monotonic functions
- Scope
- Global Interpretability
- Local Interpretability:
- Global Versus Local Analysis Motif
- Application Domain
- model-agnostic
- model-specific
- Understanding and Trust
- Why Machine Learning for Interpretability?
- The Multiplicity of Good Models
- From Explainable to Responsible AI
- Responsibility in AI and Machine Learning
Note, we will explore a global versus local analysis motif that will be crucial when interpreting models in Driverless AI. Furthermore, we will explore a general justification for MLI and a huge problem in the field: the multiplicity of good models. At last, we will explore each technique while explaining how they can be used to understand our use case: credit card defaulting.
References
You will need the following to be able to do this self-paced course:
- Basic knowledge of Machine Learning and Statistics
- Basic knowledge of Driverless AI or doing the following self-paced course: Automatic Machine Learning Introduction with Driverless AI
- A Two-Hour Test Drive session: Test Drive is H2O.ai's Driverless AI on the AWS Cloud. No need to download software. Explore all the features and benefits of the H2O Automatic Learning Platform.
- Need a Two-Hour Test Drive session? Follow the instructions on this quick self-paced course to get a Test Drive session started.
Note: Aquarium's Driverless AI Test Drive lab has a license key built-in, so you don't need to request one to use it. Each Driverless AI Test Drive instance will be available to you for two hours, after which it will terminate. No work will be saved. If you need more time to further explore Driverless AI, you can always launch another Test Drive instance or reach out to our sales team via the contact us form.
About the Dataset
The dataset we will be using contains information about credit card clients in Taiwan from April 2005 to September 2005. Features include demographic factors, repayment statuses, history of payment, bill statements, and default payments. The data set comes from the UCI Machine Learning Repository: UCI_Credit_Card.csv This dataset has a total of 25 Features (columns) and 30,000 Clients (rows).
Download Dataset
When looking at the UCI_Credit_Card.csv, we can observe that column PAY_0 was suppose to be named PAY_1. Accordingly, we will solve this problem using a data recipe that will change the column's name to PAY_1. The data recipe has already been written and can be found here. We will load the dataset and modify it using the recipe through the recipe URL.
1. Click on + Add Dataset (Or Drag & Drop) and select </> Data Recipe URL:
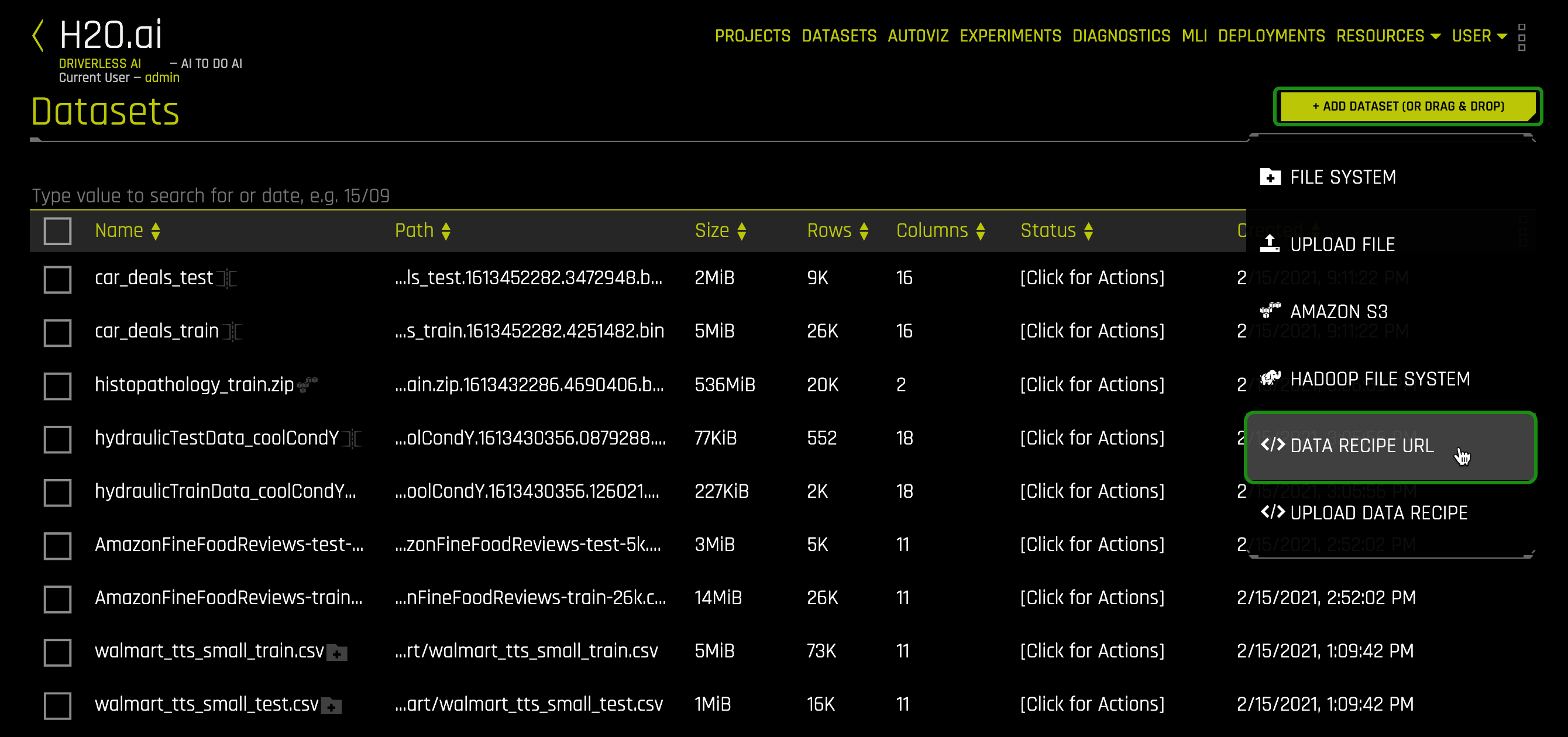
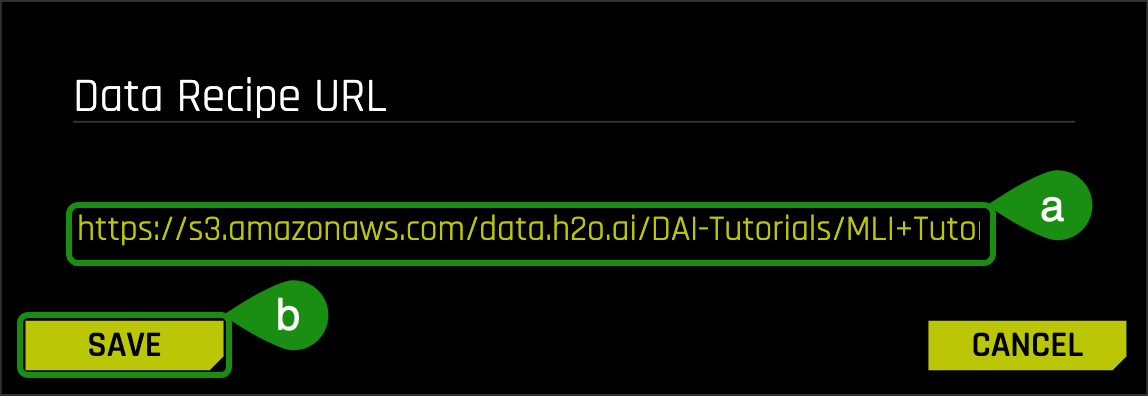
2. Copy and paste the following link in the Data Recipe URL box and click Save:
https://s3.amazonaws.com/data.h2o.ai/DAI-Tutorials/MLI+Tutorials/uci_credit_card_recipe.py
After it imports successfully, you will see the following CSV on the DATASETS page: UCI_Credit_Card.csv.
Details and Launch Experiment
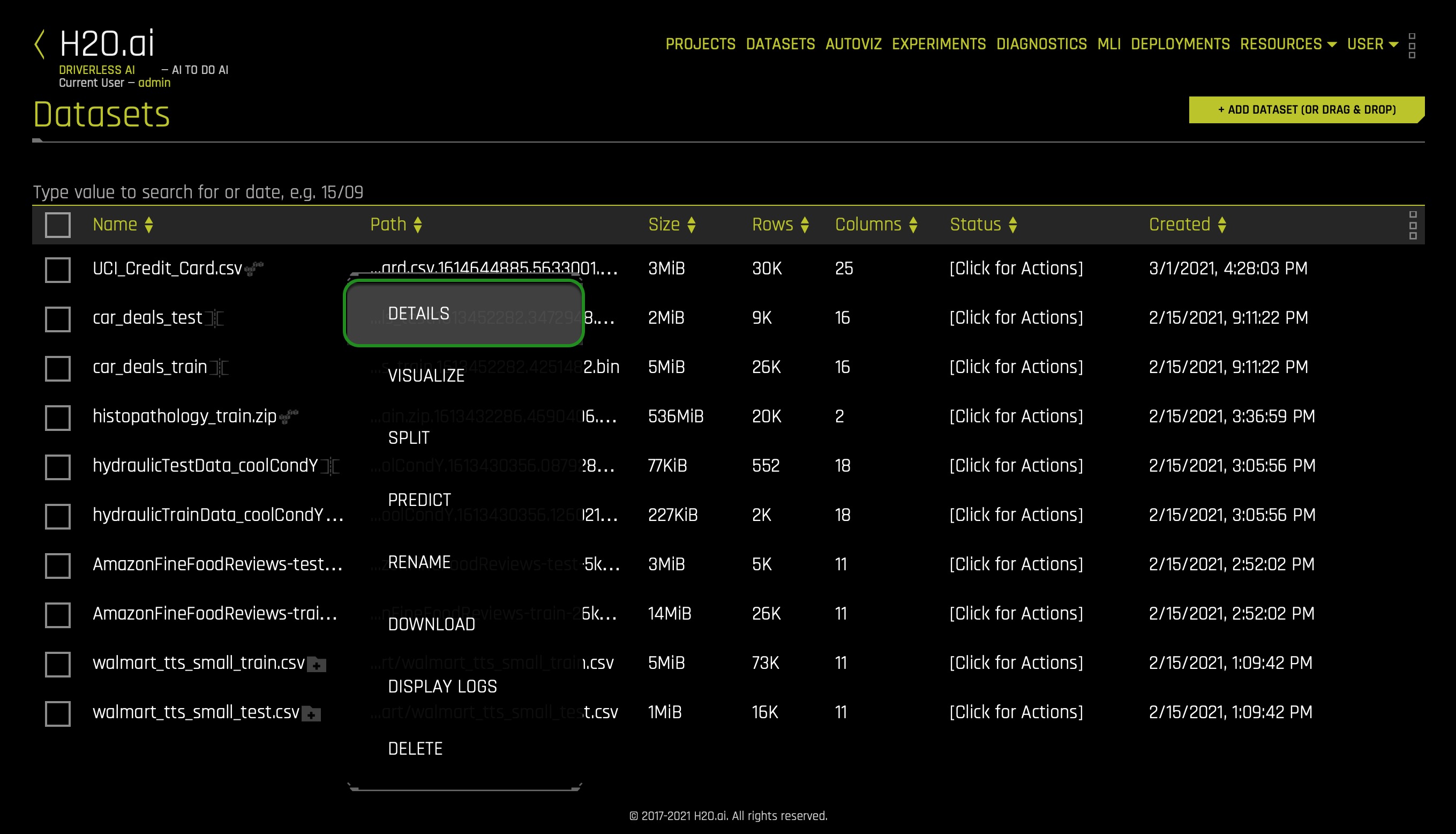
1. Click on the UCI_Credit_Card.csv then select Details:
2. Before we run our experiment, let's have a look at the dataset columns:
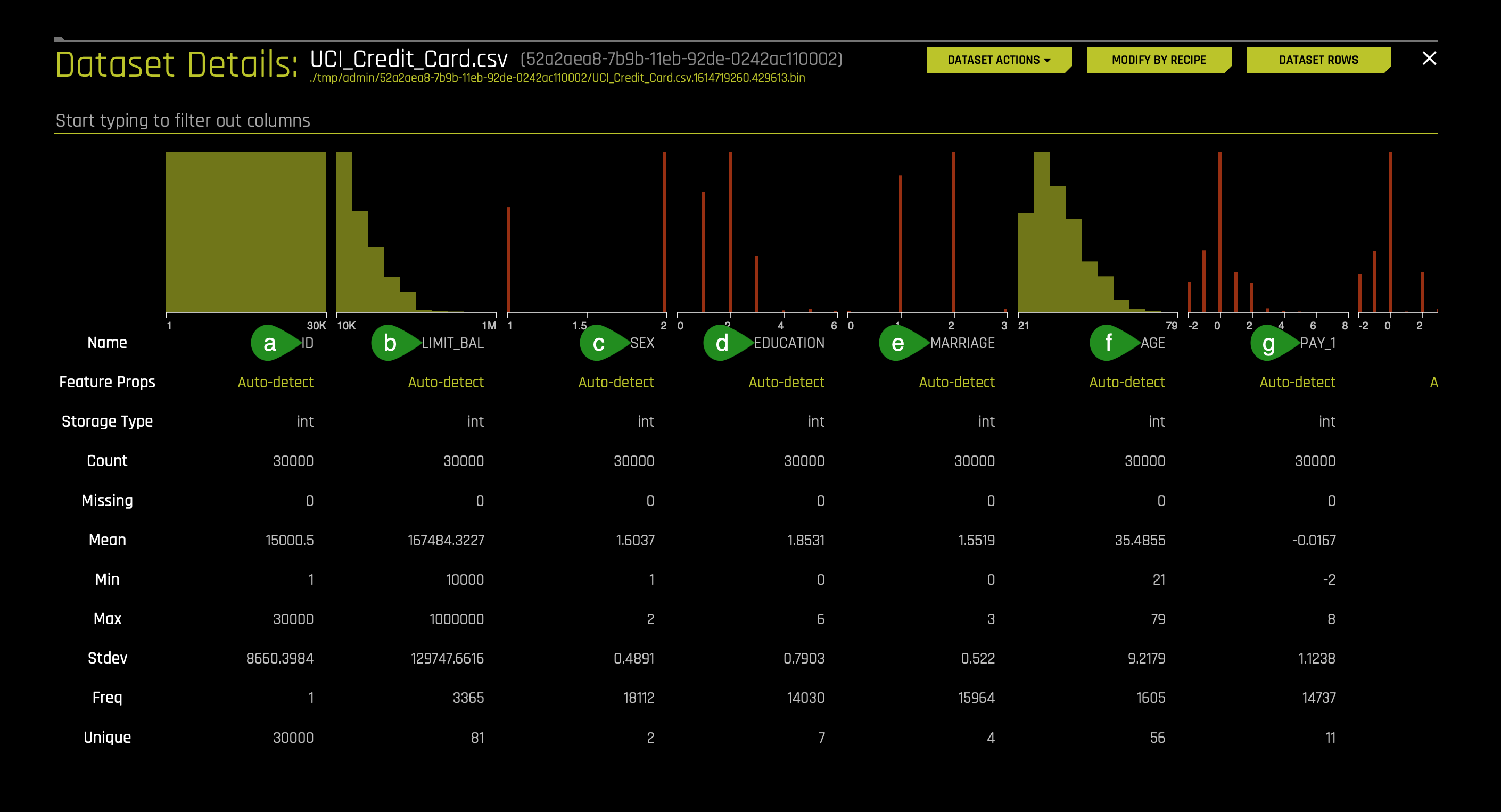
- Things to Note:
a. ID - Row identifier (which will not be used for this experiment)
b. LIMIT_BAL - Amount of the given credit: it includes the individual consumer credit and family (supplementary) credit
c. Sex - Gender (1 = male; 2 = female)
d. EDUCATION- Education (1 = graduate school; 2 = university; 3 = high school; 4 = others)
e. MARRIAGE - Marital status (1 = married; 2 = single; 3 = others)
f. Age
g. PAY_1 - PAY_6: History of past payment:
- -2: No consumption
- -1: Paid in full
- 0: The use of revolving credit
- 1 = payment delay for one month
- 2 = payment delay for two months; ...;
- 6 = payment delay for six months
Continue scrolling the current page to see more columns.
- BILL_AMT1 - BILL_AMT6 - Amount of bill statement
- PAY_AMT1 -PAY_AMT6 - Amount of previous payment
- default.payment.next.month - Default (1: Yes, 0: No)
3. Now, return to the Datasets page.
4. Click on the UCI_Credit_Card.csv, then select Predict.
5. Select Not Now on the "First-time Driverless AI" box, the following will appear:
As you might have noticed in the dataset, we have a feature that can tell us whether a client defaulted on their next month's payment. In other words, default.payment.next.month tells us if PAY_7 defaulted (PAY_7 is not a column in our dataset). As mentioned in the Objective task, we will be creating a classification model to predict whether someone will be defaulting on their next payment, in this case, on PAY_7.
6. Click on target column and select default.payment.next.month:

7. For our Training Settings, adjust the settings to:
- Accuracy: 6
- Time: 4
- Interpretability: 7
- Scorer: AUC

8. Once you have updated your experiment settings, click on Launch Experiment.
While we wait for the experiment to finish, let's explore some crucial concepts that will help us achieve interpretability in our model.
External URLs to the data:
Overivew
For decades, common sense has deemed the complex, intricate formulas created by training machine learning algorithms to be uninterpretable. While it is unlikely that nonlinear, non-monotonic, and even non-continuous machine-learned response functions will ever be as directly interpretable as more traditional linear models, great advances have been made in recent years [2]. H2O Driverless AI incorporates a number of contemporary approaches to increase the transparency and accountability of complex models and to enable users to debug models for accuracy and fairness including:
- Decision tree surrogate models [3]
- Individual conditional expectation (ICE) plots [4]
- K local interpretable model-agnostic explanations (K-LIME)
- Leave-one-covariate-out (LOCO) local feature importance [5]
- Partial dependence plots [6]
- Random forest feature importance [6]
Note: we will cover the above approaches, and we will explore various concepts around its primary functions. As well, for each approach, we will highlight the following points:
- Scope of Interpretability
- Appropriate Response Function Complexity
- Understanding and Trust
- Application Domain
Machine Learning Interpretability Taxonomy
In the context of machine learning models and results, interpretability has been defined as the ability to explain or to present in understandable terms to a human [8]. Of course, interpretability and explanations are subjective and complicated subjects, and a previously defined taxonomy has proven useful for characterizing interpretability in greater detail for various explanatory techniques [2]. Following Ideas on Interpreting Machine Learning, presented approaches will be described in terms of response function complexity, scope, application domain, understanding, and trust.
Response Function Complexity
The more complex a function, the more difficult it is to explain. Simple functions can be used to explain more complex functions, and not all explanatory techniques are a good match for all types of models. Hence, it's convenient to have a classification system for response function complexity.
- Linear, monotonic functions: Response functions created by linear regression algorithms are probably the most popular, accountable, and transparent class of machine learning models. These models will be referred to here as linear and monotonic. They are transparent because changing any given input feature (or sometimes a combination or function of an input feature) changes the response function output at a defined rate, in only one direction, and at a magnitude represented by a readily available coefficient. Monotonicity also enables accountability through intuitive, and even automatic, reasoning about predictions. For instance, if a lender rejects a credit card application, they can say exactly why because their probability of default model often assumes that credit scores, account balances, and the length of credit history are linearly and monotonically related to the ability to pay a credit card bill. When these explanations are created automatically and listed in plain English, they are typically called reason codes. In Driverless AI, linear and monotonic functions are fit to very complex machine learning models to generate reason codes using a technique known as K-LIME.
- Nonlinear, monotonic functions: Although most machine learned response functions are nonlinear, some can be constrained to be monotonic with respect to any given input feature. While there is no single coefficient that represents the change in the response function induced by a change in a single input feature, nonlinear and monotonic functions are fairly transparent because their output always changes in one direction as a single input feature changes.Nonlinear, monotonic response functions also enable accountability through the generation of both reason codes and feature importance measures. Moreover, nonlinear, monotonic response functions may even be suitable for use in regulated applications. In Driverless AI, users may soon be able to train nonlinear, monotonic models for additional interpretability.
- Nonlinear, non-monotonic functions: Most machine learning algorithms create nonlinear, non-monotonic response functions. This class of functions are typically the least transparent and accountable of the three classes of functions discussed here. Their output can change in a positive or negative direction and at a varying rate for any change in an input feature. Typically, the only standard transparency measure these functions provide are global feature importance measures. By default, Driverless AI trains nonlinear, non-monotonic functions.
Scope
Traditional linear models are globally interpretable because they exhibit the same functional behavior throughout their entire domain and range. Machine learning models learn local patterns in training data and represent these patterns through complex behavior in learned response functions. Therefore, machine-learned response functions may not be globally interpretable, or global interpretations of machine-learned functions may be approximate. In many cases, local explanations for complex functions may be more accurate or simply more desirable due to their ability to describe single predictions.
Global Interpretability: Some of the presented techniques above will facilitate global transparency in machine learning algorithms, their results, or the machine-learned relationship between the inputs and the target feature. Global interpretations help us understand the entire relationship modeled by the trained response function, but global interpretations can be approximate or based on averages.
Local Interpretability: Local interpretations promote understanding of small regions of the trained response function, such as clusters of input records and their corresponding predictions, deciles of predictions and their corresponding input observations, or even single predictions. Because small sections of the response function are more likely to be linear, monotonic, or otherwise well- behaved, local explanations can be more accurate than global explanations.
Global Versus Local Analysis Motif: Driverless AI provides both global and local explanations for complex, nonlinear, non-monotonic machine learning models. Reasoning about the accountability and trustworthiness of such complex functions can be difficult, but comparing global versus local behavior is often a productive starting point. A few examples of global versus local investigation include:
- For observations with globally extreme predictions, determine if their local explanations justify their extreme predictions or probabilities.
- For observations with local explanations that differ drastically from global explanations, determine if their local explanations are reasonable.
- For observations with globally median predictions or probabilities, analyze whether their local behavior is similar to the model's global behavior.
Application Domain
Another important way to classify interpretability techniques is to determine whether they are model-agnostic or model-specific.
- Model-agnostic: meaning they can be applied to different types of machine learning algorithms.
- Model-specific: techniques that are only applicable for a single type of class of algorithms.
In Driverless AI, decision tree surrogate, ICE, K-LIME, and partial dependence are all model- agnostic techniques, whereas LOCO and random forest feature importance are model-specific techniques.
Understanding and Trust
Machine learning algorithms and the functions they create during training are sophisticated, intricate, and opaque. Humans who would like to use these models have basic, emotional needs to understand and trust them because we rely on them for our livelihoods or because we need them to make important decisions for us. The techniques in Driverless AI enhance understanding and transparency by providing specific insights into the mechanisms and results of the generated model and its predictions. The techniques described here enhance trust, accountability, and fairness by enabling users to compare model mechanisms and results to domain expertise or reasonable expectations and by allowing users to observe or ensure the stability of the Driverless AI model.
Why Machine Learning for Interpretability?
Why consider machine learning approaches over linear models for explanatory or inferential purposes? In general, linear models focus on understanding and predicting average behavior, whereas machine-learned response functions can often make accurate, but more difficult to explain, predictions for subtler aspects of modeled phenomenon. In a sense, linear models are approximate but create very exact explanations, whereas machine learning can train more exact models but enables only approximate explanations. As illustrated in figures 1 and 2, it is quite possible that an approximate explanation of an exact model may have as much or more value and meaning than an exact interpretation of an approximate model. In practice, this amounts to use cases such as more accurate financial risk assessments or better medical diagnoses that retain explainability while leveraging sophisticated machine learning approaches.
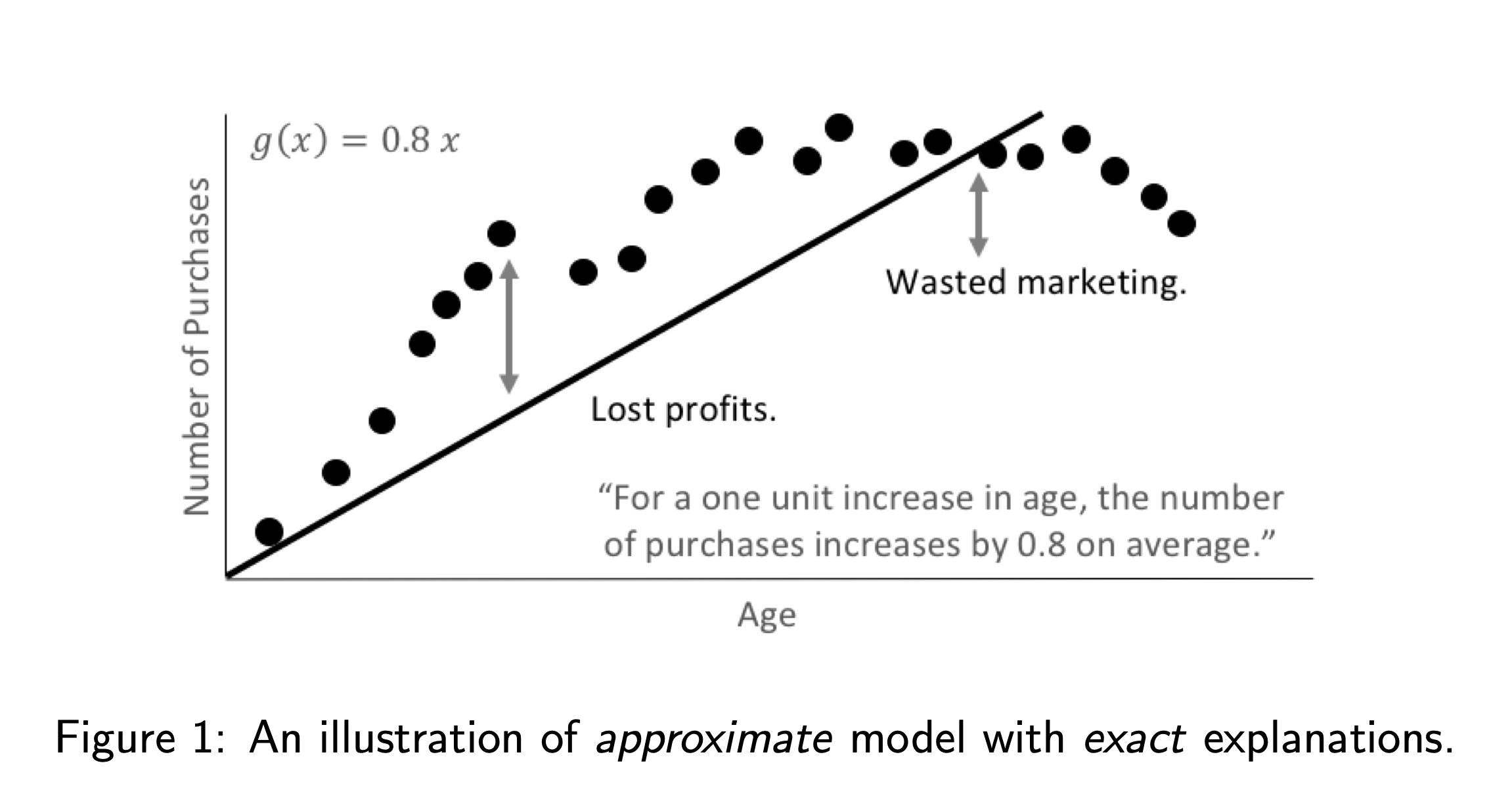
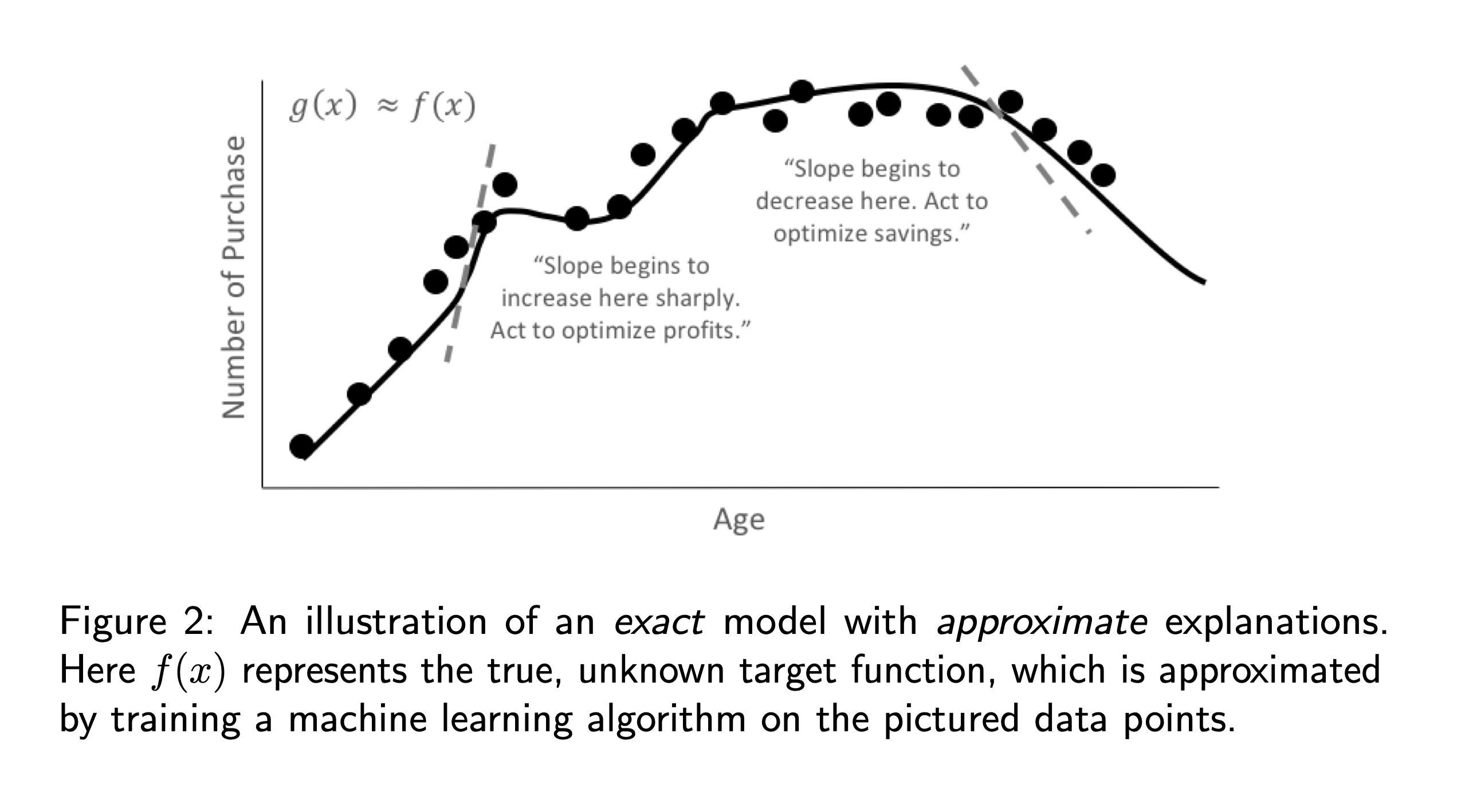
Moreover, the use of machine learning techniques for inferential or predictive purposes does not preclude using linear models for interpretation [8]. In fact, it is usually a heartening sign of stable and trustworthy results when two different predictive or inferential techniques produce similar results for the same problem.
The Multiplicity of Good Models
It is well understood that for the same set of input features and prediction targets, complex machine learning algorithms can produce multiple accurate models with very similar, but not the same, internal architectures [6]. This alone is an obstacle to interpretation, but when using these types of algorithms as interpretation tools or with interpretation tools, it is important to remember that details of explanations can change across multiple accurate models. This instability of explanations is a driving factor behind the presentation of multiple explanatory results in Driverless AI, enabling users to find explanatory information that is consistent across multiple modeling and interpretation techniques.
From Explainable to Responsible AI
AI and Machine Learning are front and center in the news daily. The initial reaction to "explaining" or understanding a created model has been centered around the concept of explainable AI, which is the technology to understand and trust a model with advanced techniques such as Lime, Shapley, Disparate Impact Analysis, and more.
H2O.ai has been innovating in the area of explainable AI for the last three years. However, it has become clear that explainable AI is not enough. Companies, researchers, and regulators would agree that responsible AI encompasses not just the ability to understand and trust a model but includes the ability to address ethics in AI, regulation in AI, and the human side of how we move forward with AI; well, in a responsible way.
Responsibility in AI and Machine Learning
Explainability and interpretability in the machine learning space have grown tremendously since we first developed Driverless AI. With that in mind, it is important to frame the larger context in which our interpretability toolkit falls. It is worth noting that since H2O.ai developed this training, the push towards regulation, oversight, and ML model auditing has increased. As a result, responsible AI has become a critical requirement for firms looking to make artificial intelligence part of their operations. There have been many recent developments globally around responsible AI, and the following themes encompass such developments: fairness, transparency, explainability, interpretability, privacy, and security. As the field has evolved, many definitions and concepts have come into the mainstream; below, we outline H2O.ai's respective definitions and understanding around the factors that make up responsible AI:
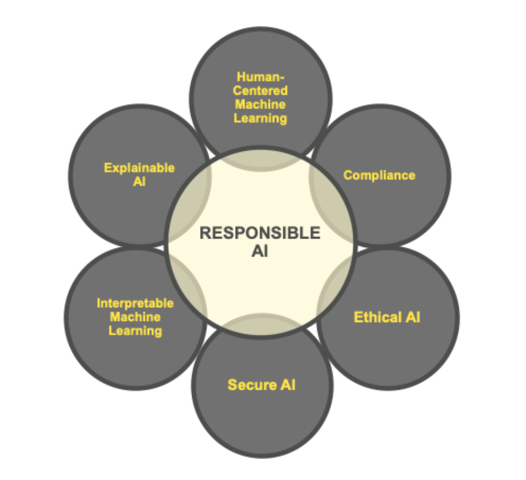
- Human-Centered ML: user interactions with AI and ML systems.
- Compliance: whether that's with GDPR, CCPA, FCRA, ECOA, or other regulations, as an additional and crucial aspect of responsible AI.
- Ethical AI: sociological fairness in machine learning predictions (i.e., whether one category of person is being weighted unequally).
- Secure AI: debugging and deploying ML models with similar counter-measures against insider and cyber threats as seen in traditional software.
- Interpretable Machine Learning: transparent model architectures and increasing how intuitive and understandable ML models can be.
- Explainable AI (XAI): the ability to explain a model to someone after it has been developed.
By now, your experiment should be completed (if not, give it a bit more time). Let's look at how we can generate an MLI report after our experiment is complete. This report will give us access to global and local explanations for our machine learning models.
References
- [2] Patrick Hall, Wen Phan, and Sri Satish Ambati. Ideas on interpreting machine learning. O'Reilly Ideas, 2017.
- [3] Mark W. Craven and Jude W. Shavlik. Extracting tree-structured repre- sentations of trained networks. Advances in Neural Information Process- ing Systems, 1996.
- [4] Alex Goldstein, Adam Kapelner, Justin Bleich, and Emil Pitkin. Peeking inside the black box: Visualizing statistical learning with plots of indi- vidual conditional expectation. Journal of Computational and Graphical Statistics, 24(1), 2015
- [5] Jing Lei, Max G'Sell, Alessandro Rinaldo, Ryan J. Tibshirani, and Larry Wasserman. Distribution-free predictive inference for regression. Journal of the American Statistical Association just-accepted, 2017.
- [6] Jerome Friedman, Trevor Hastie, and Robert Tibshirani. The Elements of Statistical Learning. Springer, New York, 2001.
- [7] Leo Breiman. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Statistical Science, 16(3), 2001. URL
- [8] Finale Doshi-Velez and Been Kim. Towards a rigorous science of inter- pretable machine learning. arXiV preprint, 2017
Deeper Dive and Resources
- Hall, P., Gill, N., Kurka, M., Phan, W. (Jan 2019). Machine Learning Interpretability with H2O Driverless AI.
- On the Art and Science of Machine Learning Explanations
- An Introduction to Machine Learning Interpretability
- Testing machine learning explanation techniques
- Awesome Machine Learning Interpretability
- Concept References
- Using Artificial Intelligence and Algorithms
- Artificial Intelligence (AI) in the Securities Industry1
- MEMORANDUM FOR THE HEADS OF EXECUTIVE DEPARTMENTS AND AGENCIES:Guidance for Regulation of Artificial Intelligence Applications
- MODEL ARTIFICIAL INTELLIGENCE GOVERNANCE FRAMEWORK SECOND EDITION
- General Data Protection Regulation GDPR
- Patrick Hall, Wen Phan, and Sri Satish Ambati. Ideas on interpreting machine learning. O'Reilly Ideas, 2017
- Leo Breiman. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Statistical Science, 16(3), 2001.
- Finale Doshi-Velez and Been Kim. Towards a rigorous science of interpretable machine learning. arXiV preprint, 2017
When your experiment finishes building, you should see the following dashboard:
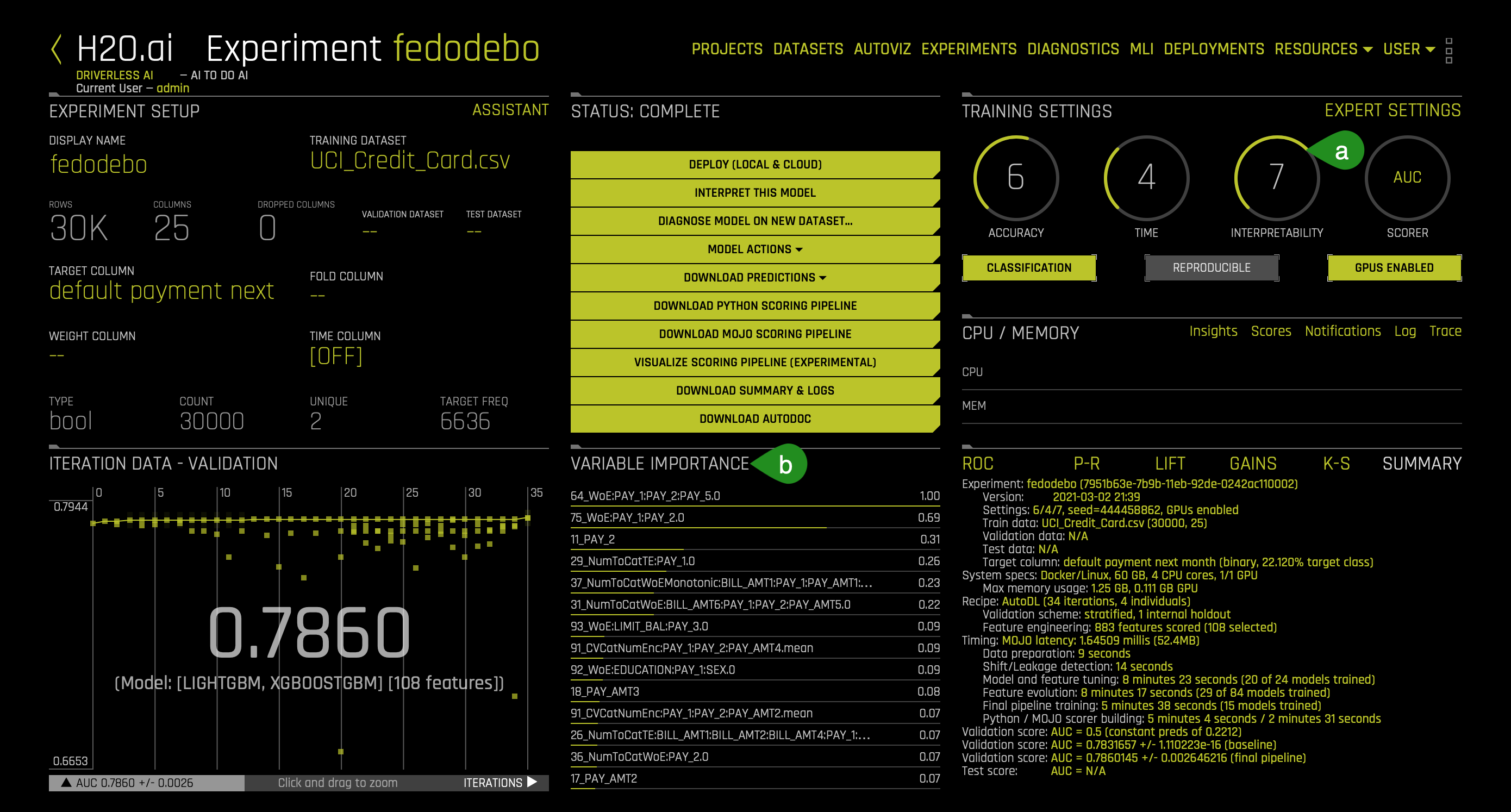
- Things to note:
a. Interpretability - The higher the interpretability, the simpler the features that Driverless AI will generate. If the interpretability is high enough, then Driverless AI will generate a monotonically constrained model. In other words, it will make the model more transparent and interpretable. In particular, it will make our metrics that we will generate easy to understand while eliminating perhaps features that will be a lot of work to understand from a perspective of interpretability. A monotonically constrained model can be enabled when Interpretability >= 7.
b. Variable Importance - Here, we can see a variety of automatically generated engineered features. Features that we will use to understand our model and its decision-making process.
1. To generate the MLI Report, select the Interpret this Model option (in the complete status section):
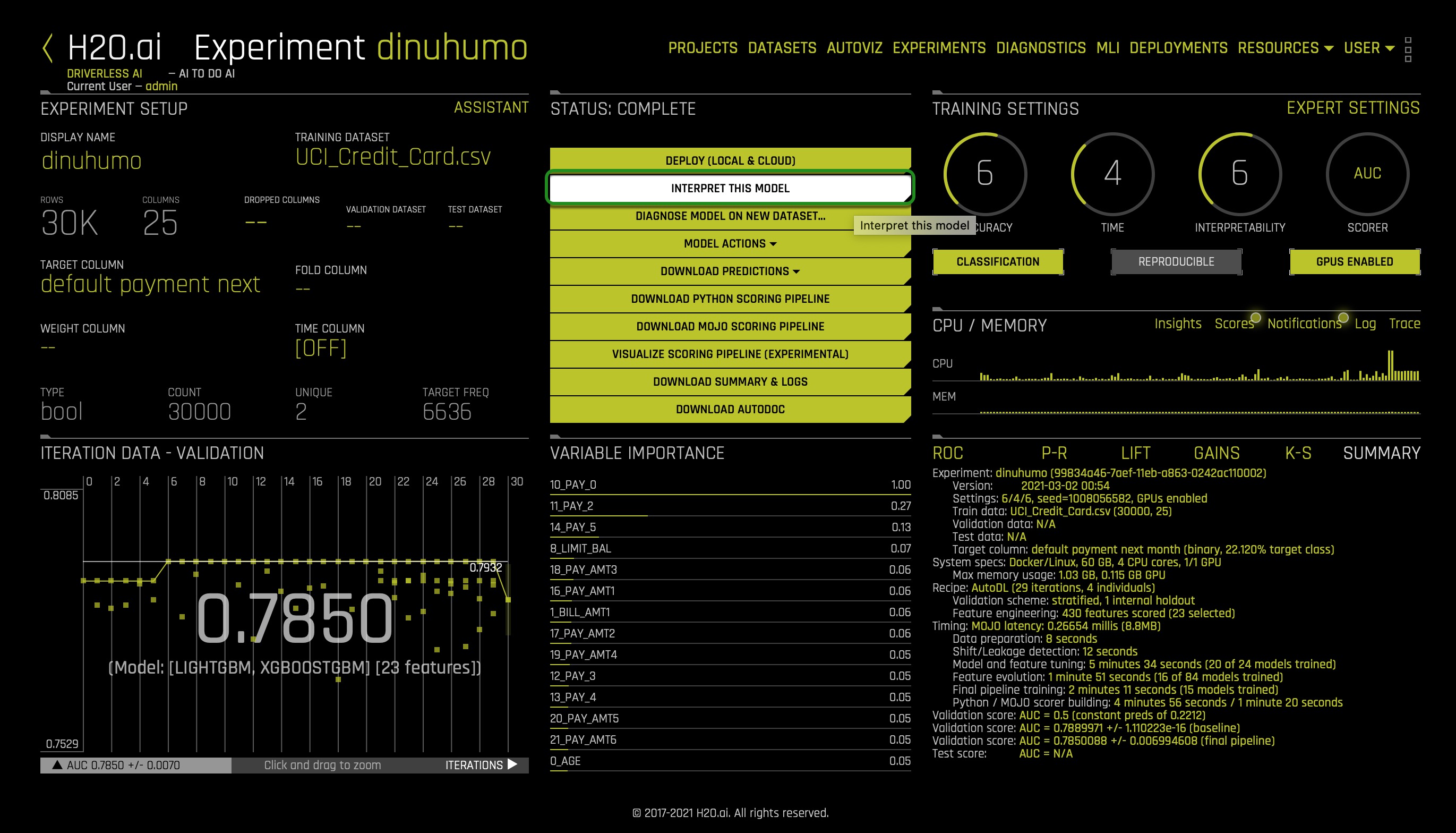
Once the MLI report is generated, the following will appear. You will know the report is ready when in the following button the value of Running and Failed equals 0: x Running | x Failed | x Done:
- Note: The Model Interpretation page (MLI) is available for non-time-series experiments.
With this task in mind, let's explore what techniques are available when understanding and interpreting your model.
1. Let's begin our exploration by looking at the Surrogate Models tab. Click the Surrogate Models tab:
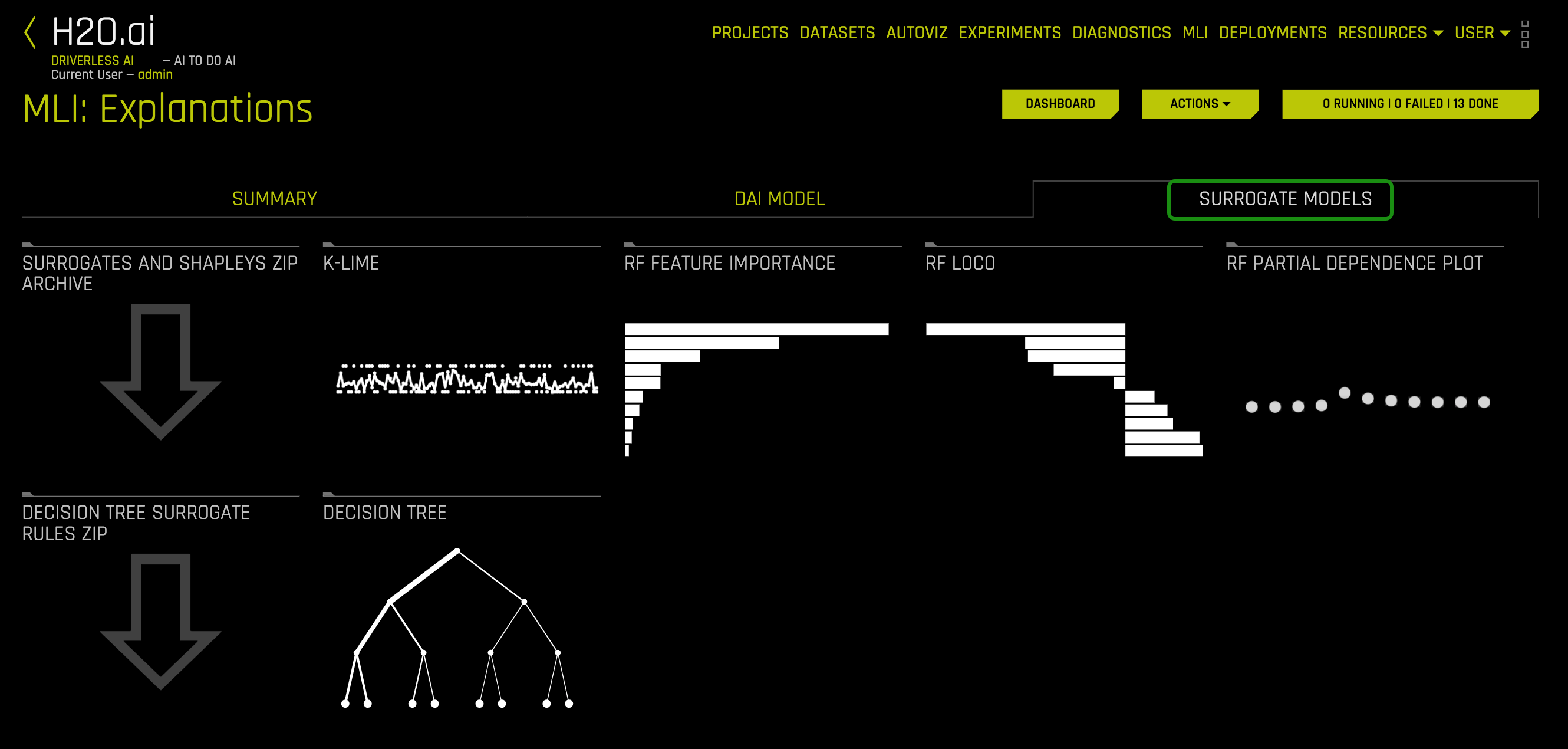
Interpretations using Surrogate Models (Surrogate Model Tab)
A surrogate model is a data mining and engineering technique in which a generally simpler model is used to explain another, usually more complex, model or phenomenon. For example, the decision tree surrogate model is trained to predict the predictions of the more complex Driverless AI model using the original model inputs. The trained surrogate model enables a heuristic understanding (i.e., not a mathematically precise understanding) of the mechanisms of the highly complex and nonlinear Driverless AI model. In other words, surrogate models are important explanations and debugging tools. They can provide global and local insights both model predictions and into model residuals or errors. However, surrogate models are approximate.
Note: The surrogate models take the system's input and attempt to model the complex Driverless AI model's predictions. Surrogate models tell us about a complex model in the original feature space.
The Surrogate Model tab is organized into tiles for each interpretation method. To view a specific plot, click the tile for the plot that you want to view. For binary classification and regression experiments, this tab includes K-LIME/LIME-SUP and Decision Tree plots as well as Feature Importance, Partial Dependence, and LOCO plots for the Random Forest surrogate model.
The following is a list of the interpretation plots from Surrogate Models:
- K-LIME and LIME-SUP
- Random Forest Feature Importance
- Random Forest Partial Dependence and Individual Conditional Expectation
- Random Forest LOCO
- Decision Tree
- NLP Surrogate (it will not be cover in this self-paced course, but you can learn more about it here)
K-LIME and LIME-SUP
The Surrogate Model Tab includes a K-LIME (K local interpretable model-agnostic explanations) or LIME-SUP (Locally Interpretable Models and Effects based on Supervised Partitioning) graph. A K-LIME graph is available by default when you interpret a model from the experiment page. When you create a new interpretation, you can instead choose to use LIME-SUP as the LIME method. Note that these graphs are essentially the same, but the K-LIME/LIME-SUP distinction provides insight into the LIME method that was used during model interpretation. For our use case, we will use the K-LIME graph only but click here to learn more about the LIME-SUP Technique.
The K-LIME Technique
This plot is available for binary classification and regression models.
K-LIME is a variant of the LIME technique proposed by Ribeiro at al (2016). K-LIME generates global and local explanations that increase the transparency of the Driverless AI model, and allow model behavior to be validated and debugged by analyzing the provided plots, and comparing global and local explanations to one-another, to known standards, to domain knowledge, and to reasonable expectations.
K-LIME creates one global surrogate generalized linear model (GLM) on the entire training data and also creates numerous local surrogate GLMs on samples formed from k-means clusters in the training data. The features used for k-means are selected from the Random Forest surrogate model's variable importance. The number of features used for k-means is the minimum of the top 25% of variables from the Random Forest surrogate model's variable importance and the max number of variables that can be used for k-means. Note, if the number of features in the dataset are less than or equal to 6, then all features are used for k-means clustering. All penalized GLM surrogates are trained to model the predictions of the Driverless AI model. The number of clusters for local explanations is chosen by a grid search in which the 𝑅^2 between the Driverless AI model predictions and all of the local K-LIME model predictions is maximized. The global and local linear model's intercepts, coefficients, 𝑅^2 values, accuracy, and predictions can all be used to debug and develop explanations for the Driverless AI model's behavior.
The parameters of the global K-LIME model give an indication of overall linear feature importance and the overall average direction in which an input variable influences the Driverless AI model predictions. The global model is also used to generate explanations for very small clusters (𝑁<20) where fitting a local linear model is inappropriate.
The in-cluster linear model parameters can be used to profile the local region, to give an average description of the important variables in the local region, and to understand the average direction in which an input variable affects the Driverless AI model predictions. For a point within a cluster, the sum of the local linear model intercept and the products of each coefficient with their respective input variable value are the K-LIME prediction. By disaggregating the K-LIME predictions into individual coefficient and input variable value products, the local linear impact of the variable can be determined. This product is sometimes referred to as a reason code and is used to create explanations for the Driverless AI model's behavior.
In the following example, reason codes are created by evaluating and disaggregating a local linear model.

And the local linear model:

It can be seen that the local linear contributions for each variable are:
- debt_to_income_ratio: 0.01 * 30 = 0.3
- credit_score: 0.0005 * 600 = 0.3
- savings_acct_balance: 0.0002 * 1000 = 0.2
Each local contribution is positive and thus contributes positively to the Driverless AI model's prediction of 0.85 for H2OAI_predicted_default. By taking into consideration the value of each contribution, reason codes for the Driverless AI decision can be derived. debt_to_income_ratio and credit_score would be the two largest negative reason codes, followed by savings_acct_balance.
The local linear model intercept and the products of each coefficient and corresponding value sum to the K-LIME prediction. Moreover it can be seen that these linear explanations are reasonably representative of the nonlinear model's behavior for this individual because the K-LIME predictions are within 5.5% of the Driverless AI model prediction. This information is encoded into English language rules which can be viewed by clicking the Explanations button (we will explore in a bit how we can access this reason codes).
Like all LIME explanations based on linear models, the local explanations are linear in nature and are offsets from the baseline prediction, or intercept, which represents the average of the penalized linear model residuals. Of course, linear approximations to complex non-linear response functions will not always create suitable explanations and users are urged to check the K-LIME plot, the local model 𝑅^2, and the accuracy of the K-LIME prediction to understand the validity of the K-LIME local explanations. When K-LIME accuracy for a given point or set of points is quite low, this can be an indication of extremely nonlinear behavior or the presence of strong or high-degree interactions in this local region of the Driverless AI response function. In cases where K-LIME linear models are not fitting the Driverless AI model well, nonlinear LOCO feature importance values may be a better explanatory tool for local model behavior. As K-LIME local explanations rely on the creation of k-means clusters, extremely wide input data or strong correlation between input variables may also degrade the quality of K-LIME local explanations.
The Global Interpretable Model Explanation Plot
1. Now, let's take a look at the Global Interpretable Model Explanation Plot. Click the K-LIME tile, the following will appear:
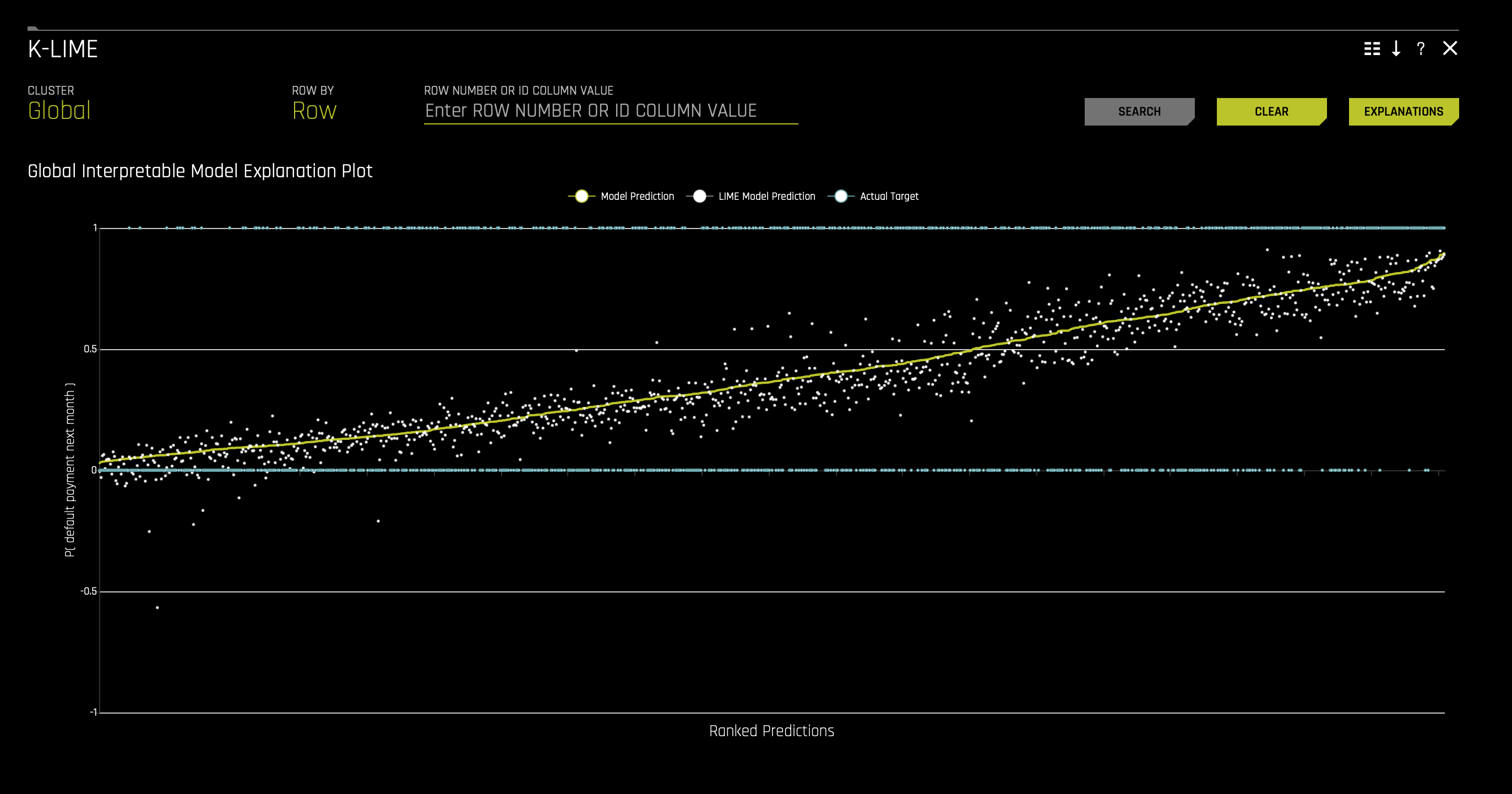
This plot shows Driverless AI model predictions and LIME model predictions in sorted order by the Driverless AI model predictions. This graph is interactive. Hover over the Model Prediction, LIME Model Prediction, or Actual Target radio buttons to magnify the selected predictions. Or click those radio buttons to disable the view in the graph. You can also hover over any point in the graph to view LIME reason codes for that value.
By default, this plot shows information for the global LIME model, but you can change the plot view to show local results from a specific cluster. The LIME plot also provides a visual indication of the linearity of the Driverless AI model and the trustworthiness of the LIME explanations. The closer the local linear model approximates the Driverless AI model predictions, the more linear the Driverless AI model and the more accurate the explanation generated by the LIME local linear models. In a moment, we will use this plot for our use case.
MLI Taxonomy: K-LIME
- Scope of Interpretability - K-LIME provides several different scales of interpretability: (a) coefficients of the global GLM surrogate provide information about global, average trends, (b) coefficients of in-segment GLM surrogates display average trends in local regions, and (c) when evaluated for specific in-segment observations, K-LIME provides reason codes on a per-observation basis.
- Appropriate Response Function Complexity - (a) K-LIME can create explanations for machine learning models of high complexity. (b) K- LIME accuracy can decrease when the Driverless AI model becomes too nonlinear.
- Understanding and Trust - (a) K-LIME increases transparency by re-vealing important input features and their linear trends. (b) K-LIME enhances accountability by creating explanations for each observation in a dataset. (c) K-LIME bolsters trust and fairness when the important features and their linear trends around specific records conform to human domain knowledge and reasonable expectations.
- Application Domain - K-LIME is model agnostic.
Use Case: Default
1. The K-LIME plot below shows the Driverless AI model predictions as a continuous curve starting on the lower left and ending in the upper right (a). The K-LIME model predictions are the discontinuous points around the Driverless AI model predictions (b).
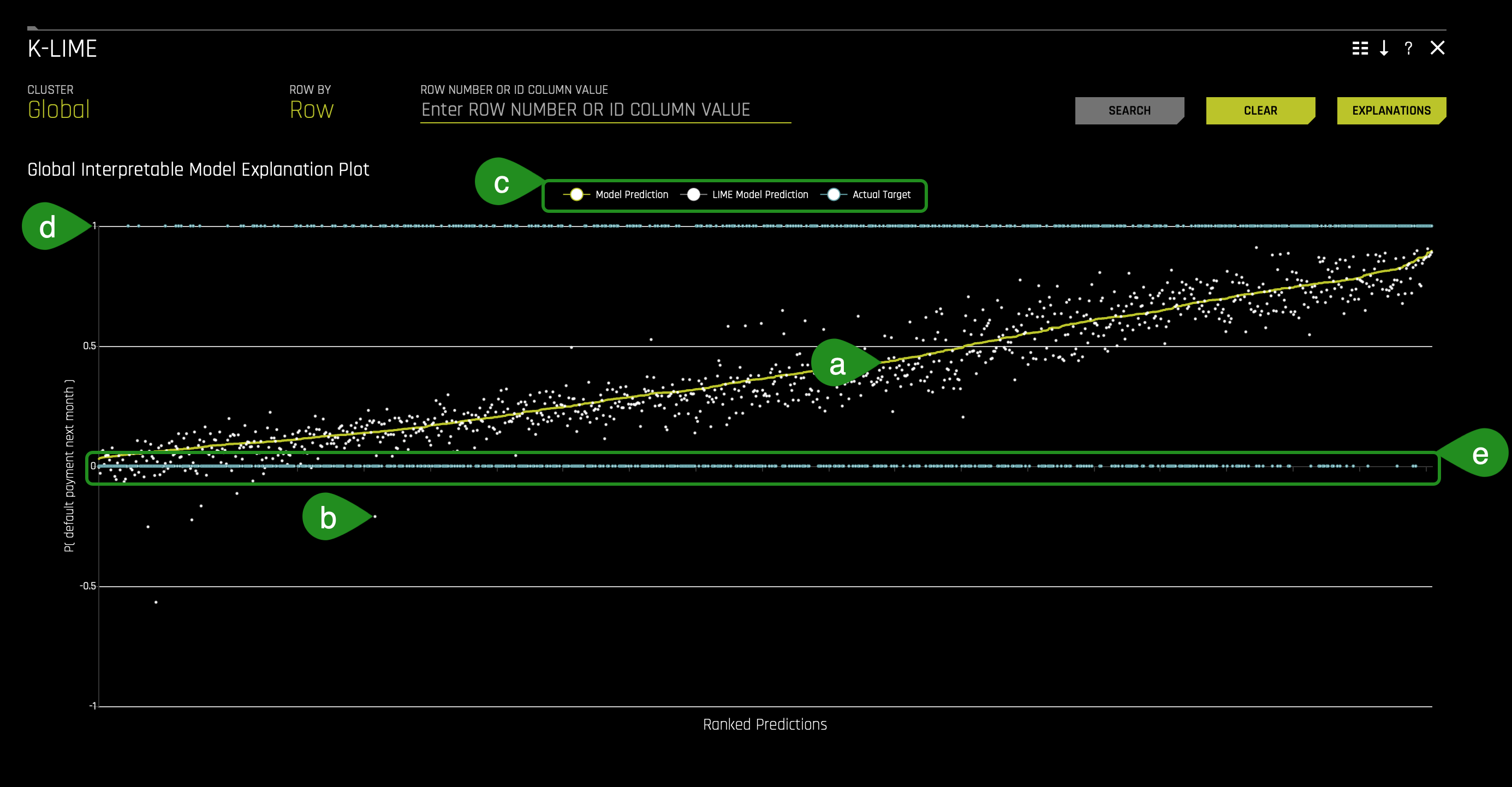
The radio buttons (c) on the top middle part of the plot allow you to enable or disable the Model Prediction, LIME Model Prediction, and Actual Target. For example, if you click the Model Prediciton radio button, it will remove the yellow curve line: the Driverless AI model predictions.
Note that Actual Target (default.payment.next.month) refers to the two blue horizontal lines: (d) clients that defaulted on their next month payment (PAY_7): 1 and (e) clients that didn't default on their next month payment (PAY_7): 0.
- Note: default.payment.next.month - Default (1: Yes, 0: No)
2. Now, click on Explanations (top right corner). The following will appear:

Considering the global explanations in the image above, we can also see that the K-LIME predictions generally follow the Driverless AI model's predictions, and the global K-LIME model explains 93.37% of the variability in the Driverless AI model predictions, indicating that global explanations are approximate, but reasonably so.
- Note the low RMSE (root-mean-square error), 0.053. We can say that the data points are not that far from the regression line. The data points are well concentrated around the line of best fit.
The image above presents global explanations for the Driverless AI model. The explanations proved a linear understanding of input features and the outcome, default.payment.next.month. According to the reason codes, PAY_1 makes the largest global, linear contributions to the Driverless AI model. As well, PAY_4 makes a large top negative global contribution.
- When PAY_1 = 2, this is associated with "default.payment.next.month" K-LIME prediction's increase by 0.38 (38%)
- When PAY_1 = 0, this is associated with "default.payment.next.month" K-LIME prediction's decrease of 0.085 (8.5%)
When you are done observing the Reason Codes, you can go back to the K-Lime plot.
3. Now, let's see if the global explanations still hold at the local level. Let's observe a particular discontinuous point around the Driverless AI model predictions. In your plot, click any high probability default point (top left corner). In our case, we have selected point 11427 and we can observe the following:
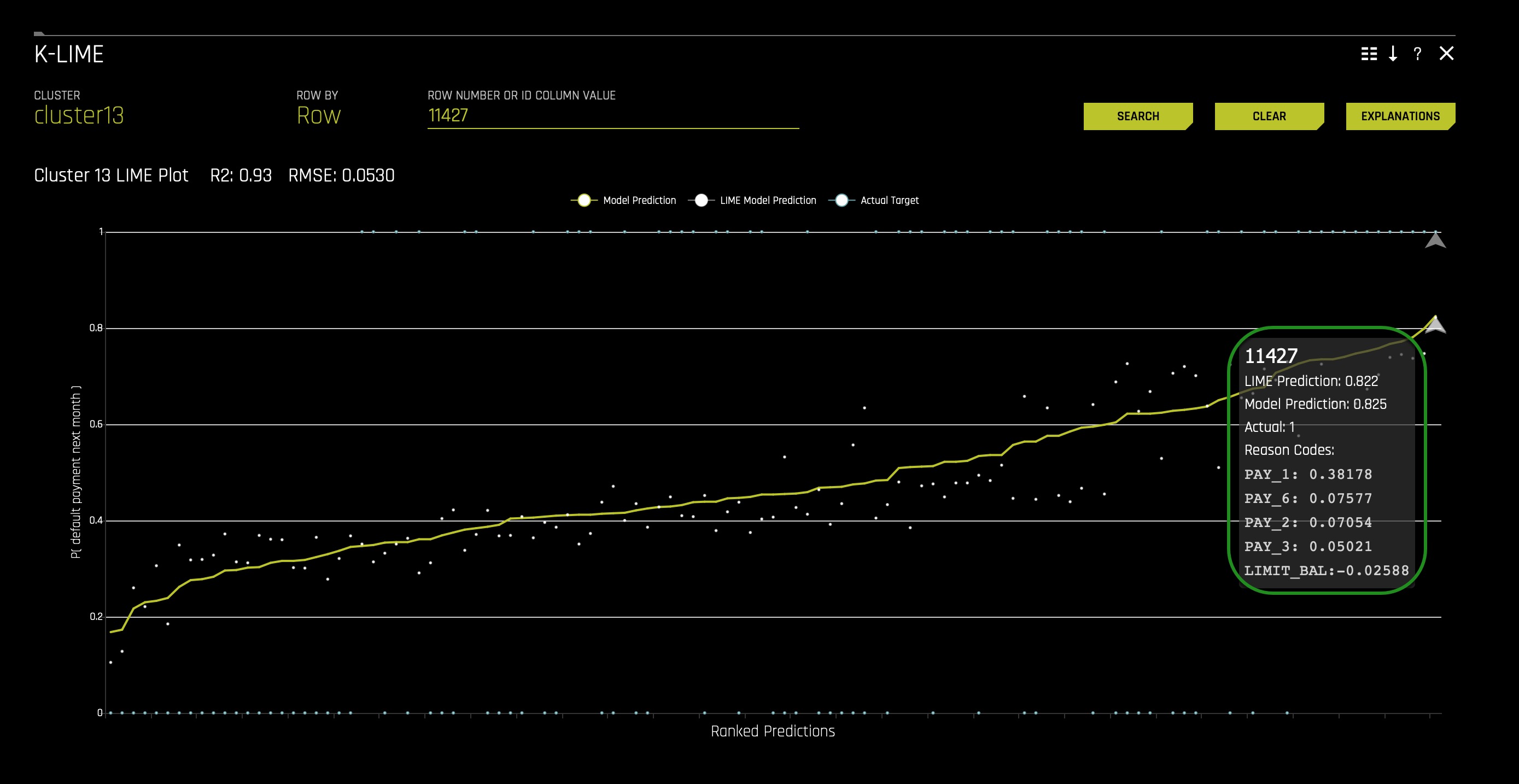
We can see that the LIME Prediction is very similar to the Model Prediction while knowing that the Actual Target is 1. When looking at the reason codes, we can see that PAY_1 was the leading feature for a high value among the LIME and Model prediction.
5. Let's further understand these reasons codes; click on the Explanations (top right corner of the tile). The following will appear:
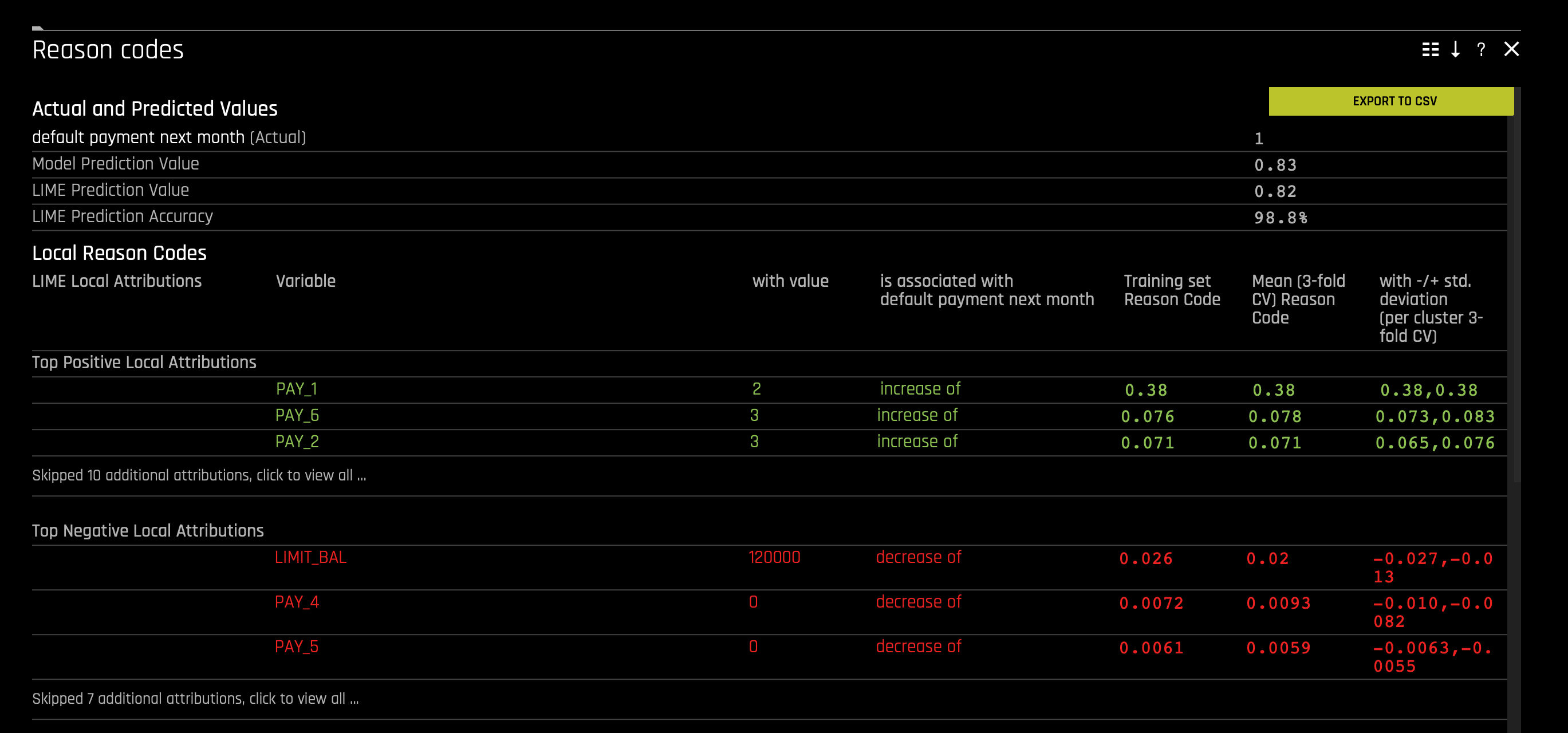
When observing the reason codes for the data point 11427, we can see that the LIME Prediction Accuracy is 98.8%; in other words, we can conclude that this prediction is relatively trustworthy. We also see that PAY_1 was around the top three features contributing to a high default prediction. In particular, PAY_1 is the top feature contributing to a high prediction of 38%. In this case, the global reason codes are validated by this local observation. Therefore, so far, it seems that being late two months on PAY_1 leads to a 38% increase in most likely to default on PAY_7 (default.payment.next.month).
Using the global versus local analysis motif to reason about the example analysis results thus far, it could be seen as a sign of explanatory stability that several globally important features are also appearing as locally important.
Now let's focus our attention on using certain Feature Importance charts to understand this global and local analysis motif.
Global Feature Importance vs Local Feature Importance
Feature importance measures the effect that a feature has on the predictions of a model. Global feature importance measures the overall impact of an input feature on the Driverless AI model predictions while taking nonlinearity and interactions into consideration. Global feature importance values give an indication of the magnitude of a feature's contribution to model predictions for all observations. Unlike regression parameters, they are often unsigned and typically not directly related to the numerical predictions of the model. Local feature importance describes how the combination of the learned model rules or parameters and an individual observation's attributes affect a model's prediction for that observation while taking nonlinearity and interactions into effect.
Random Forest Feature Importance
You can access a Random Forest (RF) Feature Importance chart on the MLI report page.
1. Click the Surrogate Models tab and click the tile with the following title: RF Feature Importance.
When the chart appears, it will not have the grey bars (local features); it will only display the yellow bars (global features). To explain this chart effectively, enter the following number in the chart's search bar (top left of the tile): 11427. This will allow for the grey bars to appear for a given observation (data point 11427).
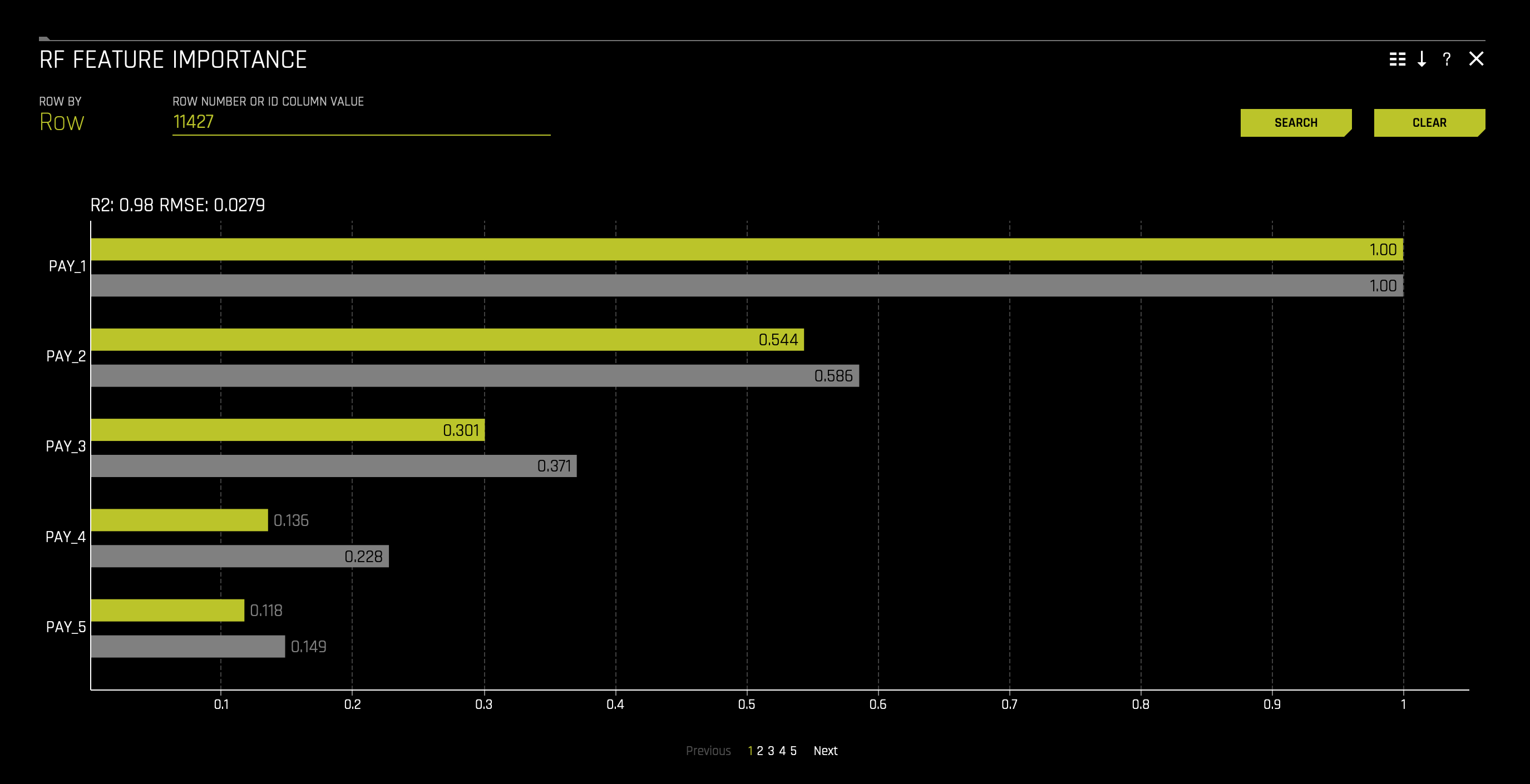
The chart can be explained as follows:
Global feature importance (yellow) is a measure of the contribution of an input variable to the overall predictions of the Driverless AI model. Global feature importance is calculated by aggregating the improvement in splitting criterion caused by a single variable across all of the decision trees in the Driverless AI model.
Local feature importance (grey) is a measure of the contribution of an input variable to a single prediction of the Driverless AI model. Local feature importance is calculated by removing the contribution of a variable from every decision tree in the Driverless AI model and measuring the difference between the prediction with and without the variable.
Both global and local variable importance are scaled so that the largest contributor has a value of 1.
LOCO Feature Importance
1. You can access a Random Forest (RF) leave-one-covariate-out chart on the MLI report page. Click the Surrogate Models tab and click the tile with the following title: RF LOCO. The following will appear:
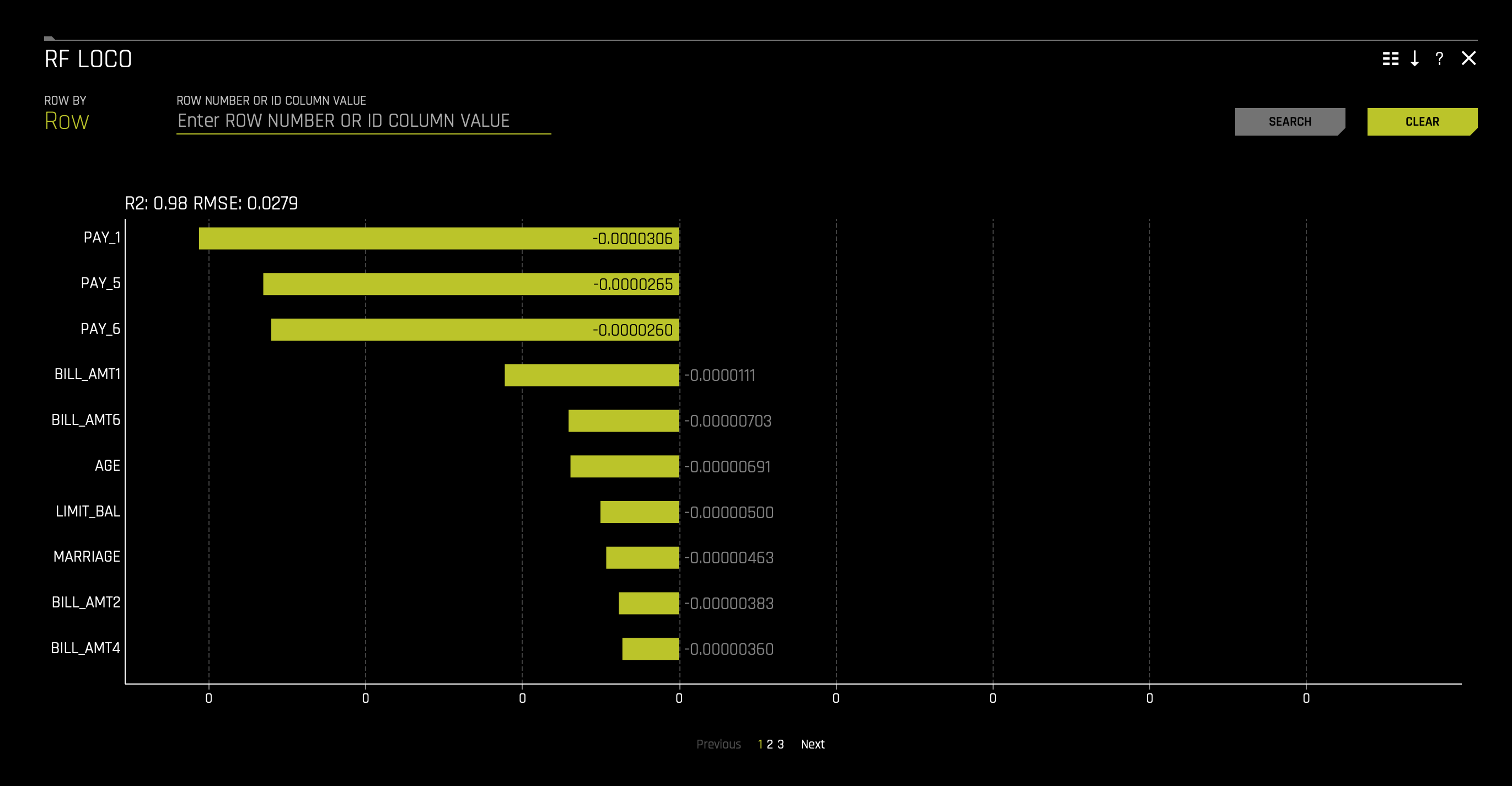
This plot is available for binary and multinomial classification models as well as regression models.
Local feature importance describes how the combination of the learned model rules or parameters and an individual row's attributes affect a model's prediction for that row while taking nonlinearity and interactions into effect. Local feature importance values reported in this plot are based on a variant of the leave-one-covariate-out (LOCO) method (Lei et al, 2017).
The LOCO-variant method for binary and regression models calculates each local feature importance by re-scoring the trained Driverless AI model for each feature in the row of interest, while removing the contribution to the model prediction of splitting rules that contain that feature throughout the ensemble. The original prediction is then subtracted from this modified prediction to find the raw, signed importance for the feature. All local feature importance values for the row are then scaled between 0 and 1 for direct comparison with global feature importance values.
The LOCO-variant method for multinomial models differs slightly in that it calculates row-wise local feature importance values by re-scoring the trained supervised model and measuring the impact of setting each variable to missing. The sum of the absolute value of differences across classes is then calculated for each dropped or replaced column.
MLI Taxonomy: Feature Importance
- Scope of Interpretability - (a) Random forest feature importance is a global interpretability measure. (b) LOCO feature importance is a local interpretability measure.
- Appropriate Response Function Complexity - Both random forest and LOCO feature importance can be used to explain tree-based response functions of nearly any complexity.
- Understanding and Trust - (a) Random forest feature importance in- creases transparency by reporting and ranking influential input features. (b) LOCO feature importance enhances accountability by creating ex- planations for each model prediction. (c) Both global and local feature importance enhance trust and fairness when reported values conform to human domain knowledge and reasonable expectations.
- Application Domain - (a) Random forest feature importance is a model- specific explanatory technique. (b) LOCO is a model-agnostic concept, but its implementation in Driverless AI is model specific.
Use Case: Default
1. On the RF Feature Importance chart, click on the Clear button located on the tile's top right corner. That will clear the chart and will only display the global features (yellow). You should see the following:
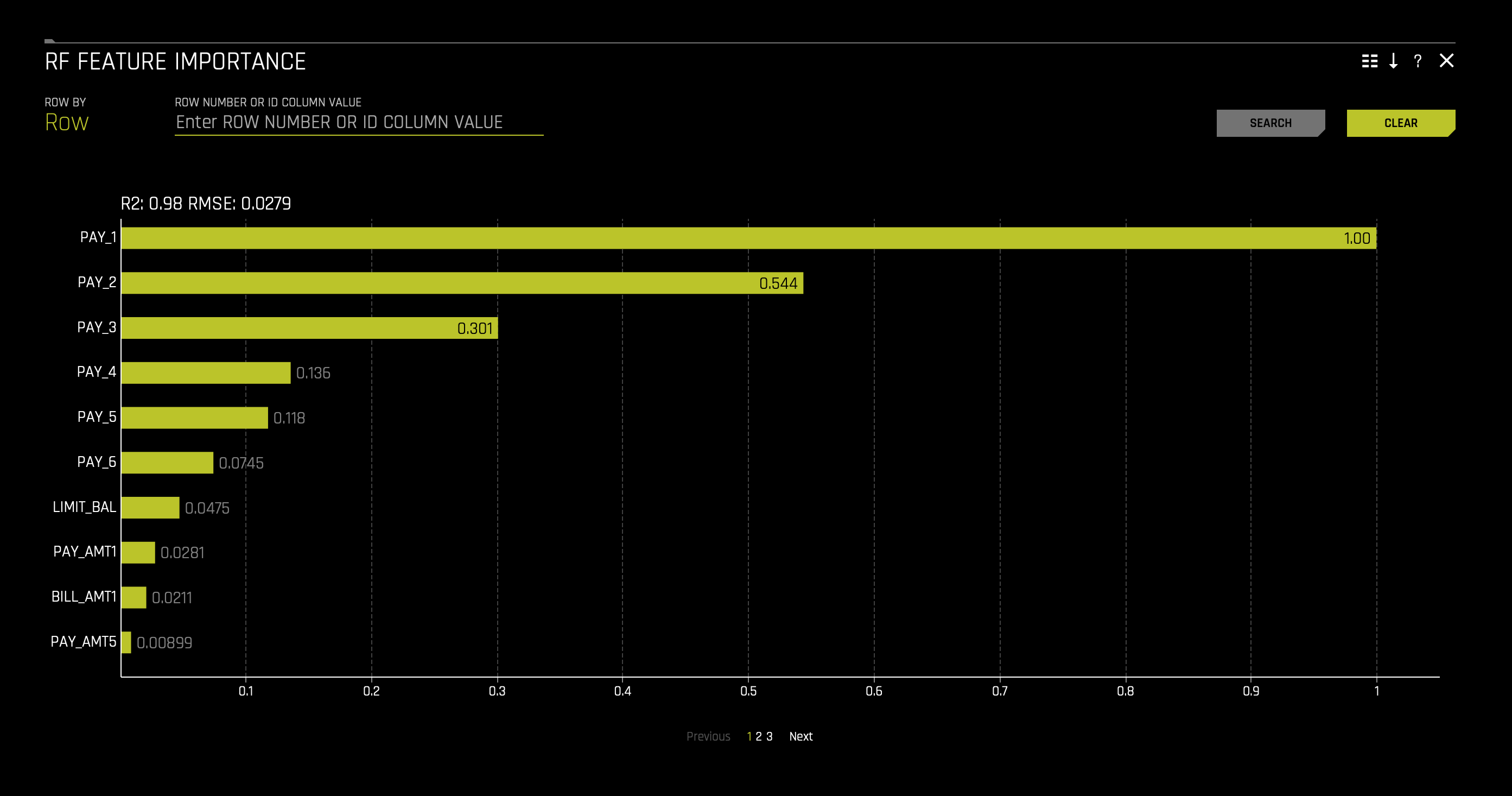
The features with the greatest importance values in the Driverless AI model are PAY_1, PAY_2, and PAY_3 as observed in the image above. Here, we can see PAY_1 is the most influential predictor on whether someone will default. As we read down, we see that recent payments don't have a huge impact on prediction when compared to the first payment. If we consider that being late two months on your first payment is bad, we can conclude that this model's predictions solely in a matter of speaking depend heavily on this notion of being two months late on PAY_0.
The RF feature importance chart matches the hypotheses created during data exploration to a large extent. Feature importance, however, does not explain the relationship between a feature and the Driverless AI model's predictions. This is where we can examine partial dependence plots.
A Partial Dependence and ICE plot is available for both Driverless AI and surrogate models.
Partial Dependece
The Partial Dependence Technique:
Partial dependence is a measure of the average model prediction with respect to an input variable. Partial dependence plots display how machine-learned response functions change based on the values of an input variable of interest while taking nonlinearity into consideration and averaging out the effects of all other input variables. Partial dependence plots are described in the Elements of Statistical Learning (Hastie et al, 2001). Partial dependence plots enable increased transparency in Driverless AI models and the ability to validate and debug Driverless AI models by comparing a variable's average predictions across its domain to known standards, domain knowledge, and reasonable expectations.
Individual Conditional Expectation (ICE)
The ICE Technique:
This plot is available for binary classification and regression models.
A newer adaptation of partial dependence plots called Individual conditional expectation (ICE) plots can be used to create more localized explanations for a single individual by using the same basic ideas as partial dependence plots. ICE Plots were described by Goldstein et al (2015). ICE values are disaggregated partial dependence, but ICE is also a type of nonlinear sensitivity analysis in which the model predictions for a single row are measured while a variable of interest is varied over its domain. ICE plots enable a user to determine whether the model's treatment of an individual row of data is outside one standard deviation from the average model behavior, whether the treatment of a specific row is valid in comparison to average model behavior, known standards, domain knowledge, and reasonable expectations, and how a model will behave in hypothetical situations where one variable in a selected row is varied across its domain.
Note: Large differences in partial dependence and ICE are an indication that strong variable interactions may be present.
The Partial Dependence Plot
This plot is available for binary classification and regression models.
1. In the Surrogate Models tab, click on the RF Partial Dependence Plot. The following will appear:
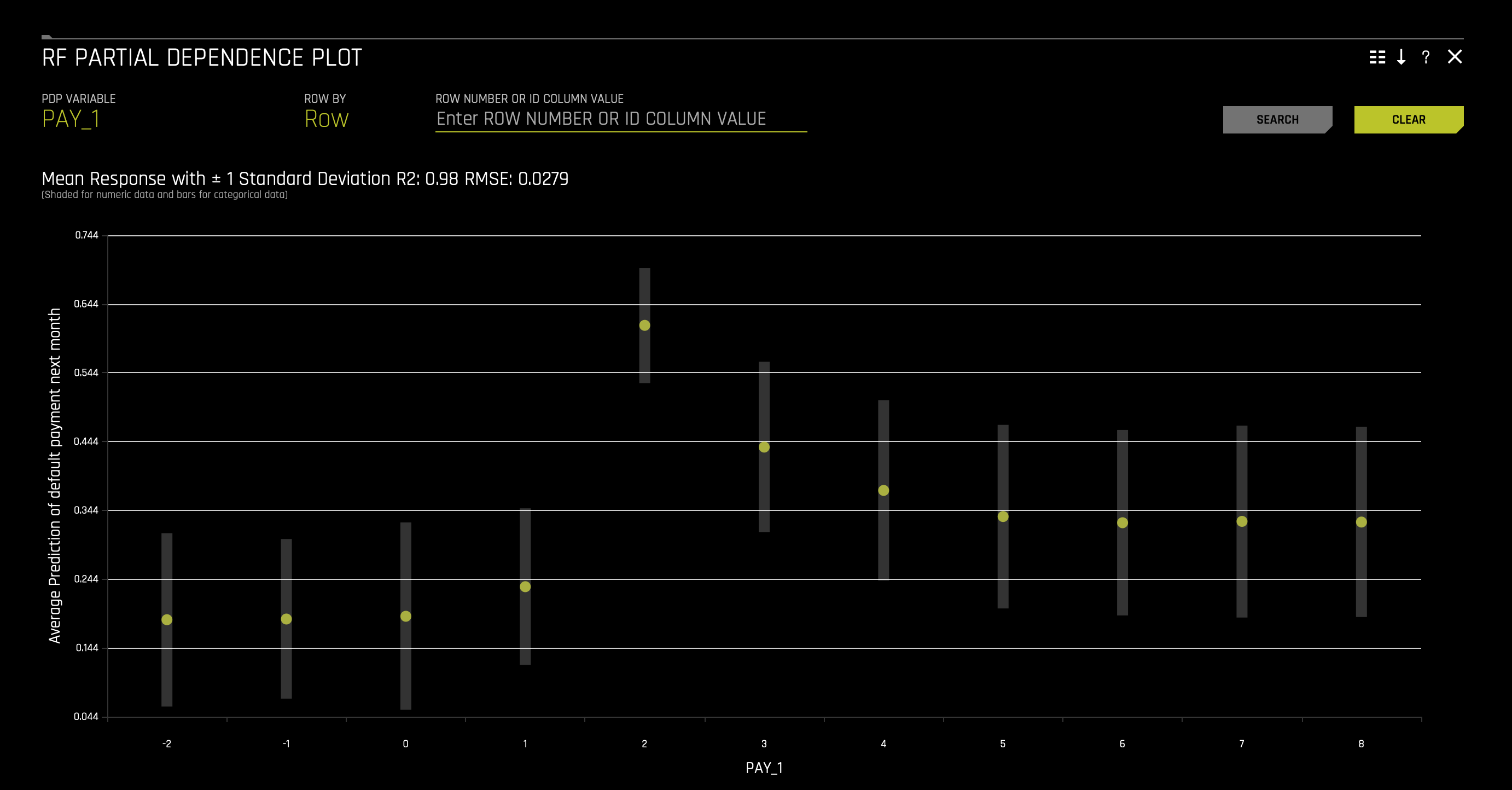
Overlaying ICE plots onto partial dependence plots allow the comparison of the Driverless AI model's treatment of certain examples or individuals to the model's average predictions over the domain of an input variable of interest.
This plot shows the partial dependence when a variable is selected and the ICE values when a specific row is selected. Users may select a point on the graph to see the specific value at that point. Partial dependence (yellow) portrays the average prediction behavior of the Driverless AI model across the domain of an input variable along with +/- 1 standard deviation bands. ICE (grey) displays the prediction behavior for an individual row of data when an input variable is toggled across its domain. Currently, partial dependence and ICE plots are only available for the top ten most important original input variables. Categorical variables with 20 or more unique values are never included in these plots.
MLI Taxonomy: Partial Dependence and ICE
- Scope of Interpretability: (a) Partial dependence is a global interpretability measure. (b) ICE is a local interpretability measure.
- Appropriate Response Function Complexity - Partial dependence and ICE can be used to explain response functions of nearly any complexity.
- Understanding and Trust - (a) Partial dependence and ICE increase understanding and by describing the nonlinear behavior of complex response functions. (b) Partial dependence and ICE enhance trust, accountability, and fairness by enabling the comparison of described nonlinear behavior to human domain knowledge and reasonable expectations. (c) ICE, as a type of sensitivity analysis, can also engender trust when model behavior on simulated data is acceptable.
- Application Domain - Partial dependence and ICE are model-agnostic.
Use Case: Default
1. In the RF Partial Dependence Plot, hover over PAY_1 = 2. The following will appear:
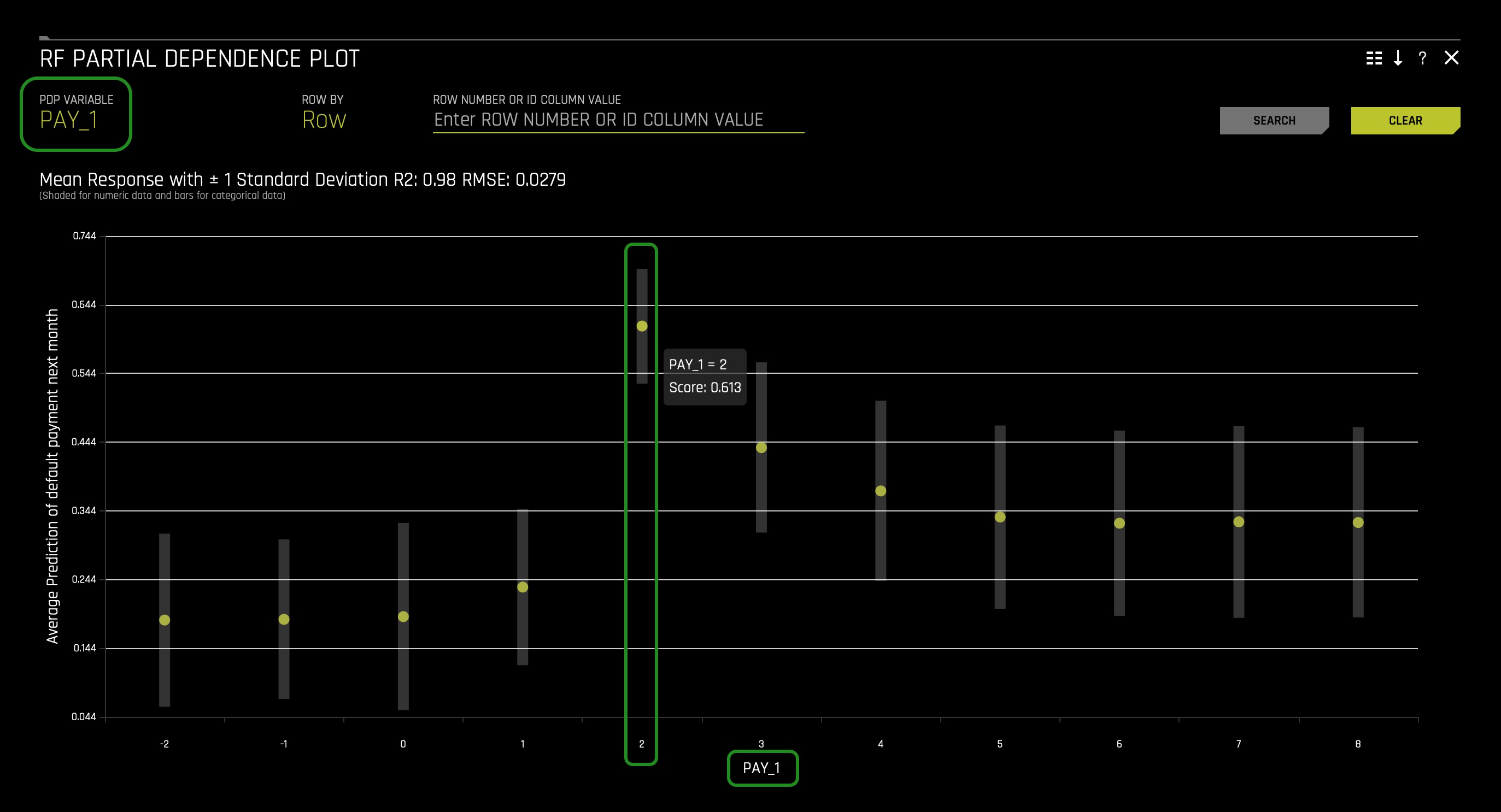
The partial dependence plots show how different feature values affect the average prediction of the Driverless AI model. The image above displays the partial dependence plot for PAY_1 and indicates that predicted default (default.payment.next.month) increases dramatically for clients two months late on PAY_1.
2. Change the PDP Variable from PAY_1 to PAY_2. You should see a similar page:
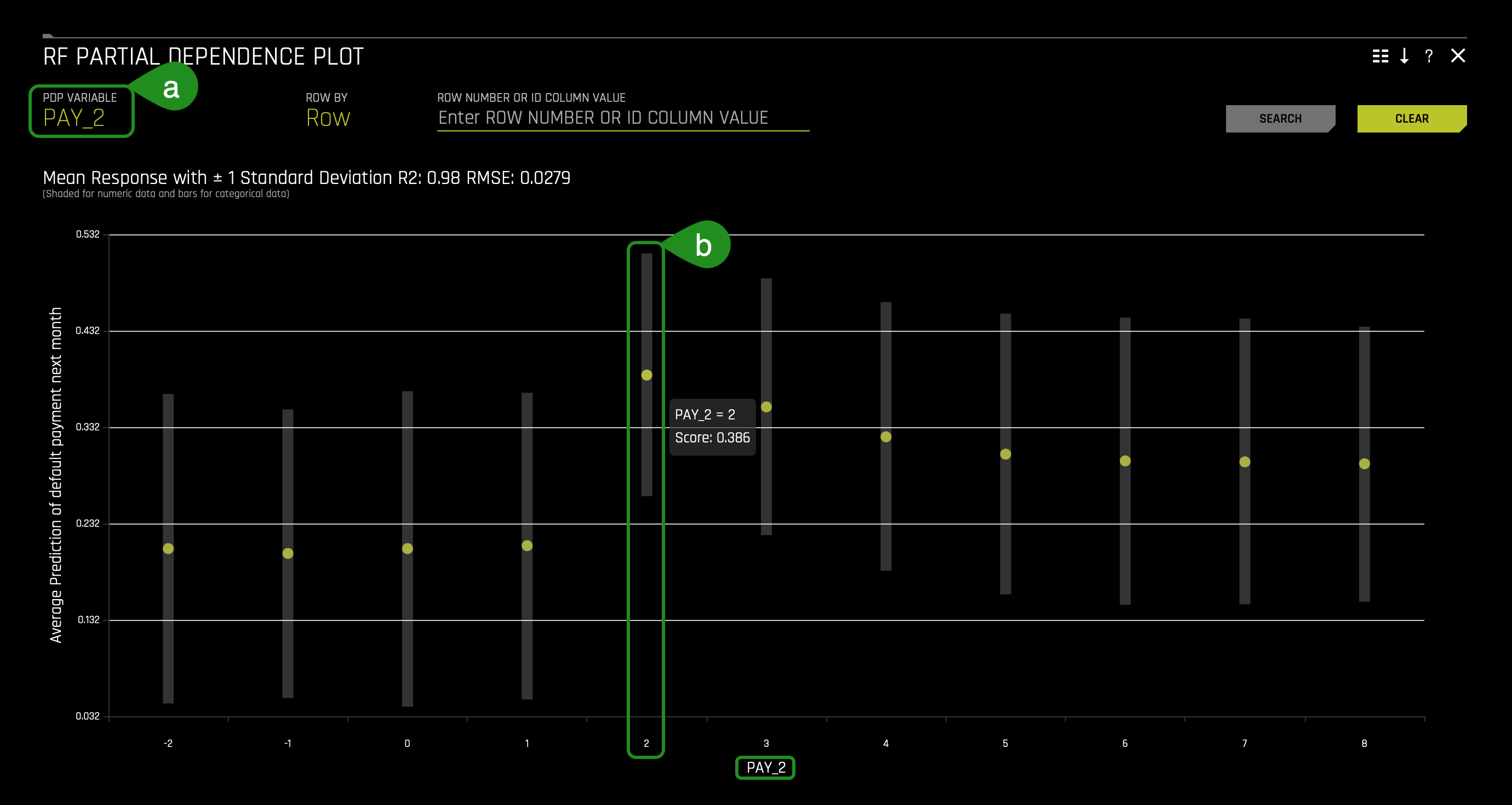
The partial dependence plots show how different feature values affect the average prediction of the Driverless AI model. The image above displays the partial dependence plot for PAY_2 and indicates that predicted default (default.payment.next.month) increases for clients two months late on PAY_2.
The above results agree with previous findings in which PAY_1, follow by PAY_2, result in high default probabilities when its value is 2. In particular, the partial dependence plots above reveal that these predictions are highly dependent on whether PAY_1 equals 2 [months late].
To further understand the impact of PAY_1 in the decision-making process, let's explore a Decision Tree Surrogate Model.
The Decision Tree Surrogate Model Technique
The decision tree surrogate model increases the transparency of the Driverless AI model by displaying an approximate flow-chart of the complex Driverless AI model's decision making process. It also displays the most important variables in the Driverless AI model and the most important interactions in the Driverless AI model. The decision tree surrogate model can be used for visualizing, validating, and debugging the Driverless AI model by comparing the displayed decision-process, important variables, and important interactions to known standards, domain knowledge, and reasonable expectations.
The Decision Tree Plot
1. In the Surrogate Models tab, click on the Decision Tree. The following will appear:
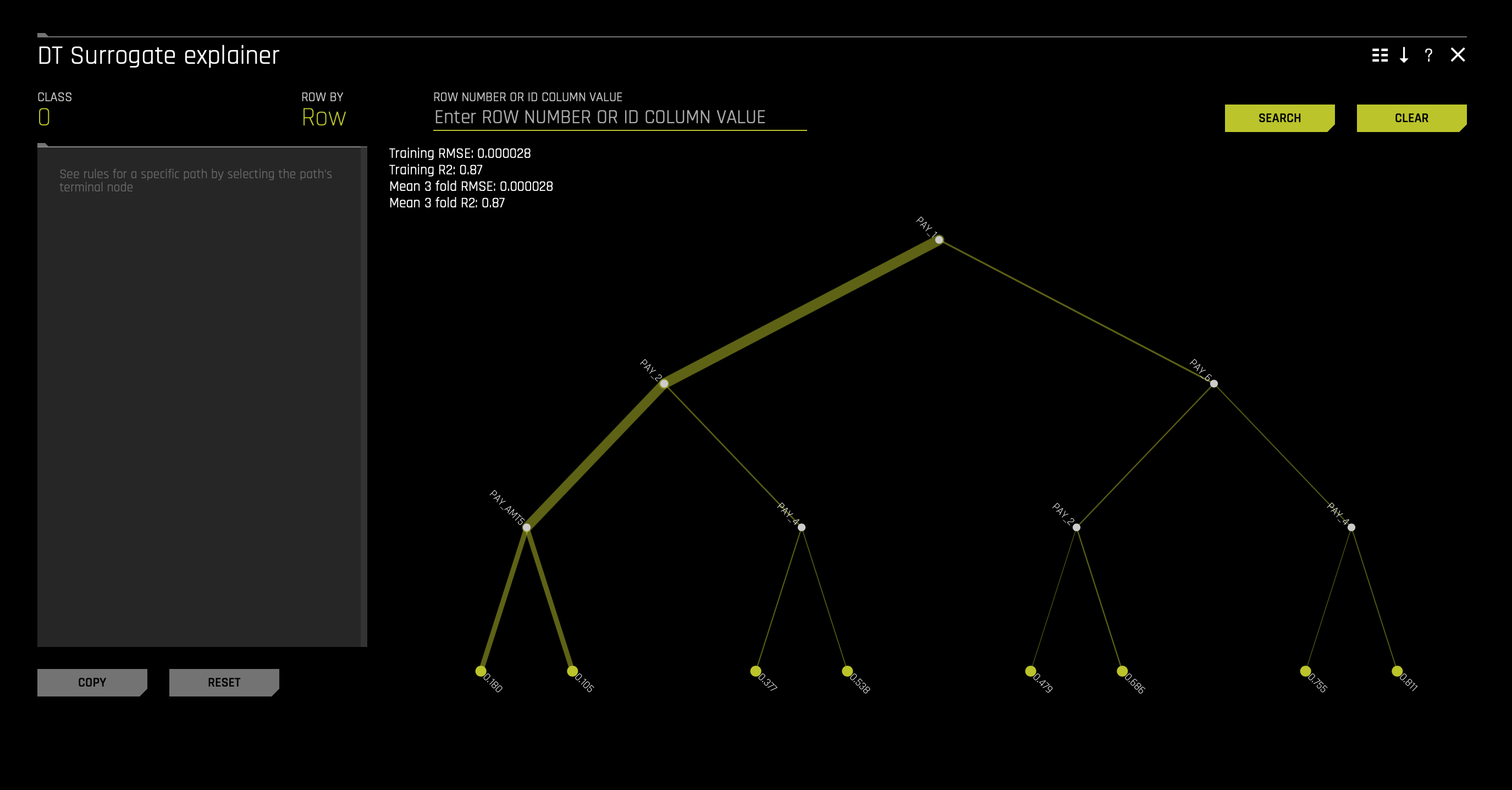
This plot is available for binary and multinomial classification models as well as regression models.
In the Decision Tree plot, the highlighted row shows the path to the highest probability leaf node and indicates the globally important variables and interactions that influence the Driverless AI model prediction for that row.
Note:
- Variables below one-another in the Decision Tree Surrogate may also have strong interactions in the Driverless AI model.
- Variables higher in the decision tree suggest higher importance in the decision-making process.
- Thick lines highlighting a particular path to a terminal node indicate a very common decision path.
- Thin lines indicate that this is a relatively rare decision path.
- The terminal nodes represent the different default probabilities.
MLI Taxonomy: Decision Tree Surrogate Models
- Scope of Interpretability - (a) Generally, decision tree surrogates provide global interpretability. (b) The attributes of a decision tree are used to explain global attributes of a complex Driverless AI model such as important features, interactions, and decision processes.
- Appropriate Response Function Complexity - Decision tree surrogate models can create explanations for models of nearly any complexity.
- Understanding and Trust - (a) Decision tree surrogate models foster understanding and transparency because they provide insight into the internal mechanisms of complex models. (b) They enhance trust, accountability, and fairness when their important features, interactions, and decision paths are in line with human domain knowledge and reasonable expectations.
- Application Domain - Decision tree surrogate models are model agnostic.
Use Case: Default
In the image above, the RMSE of 0.000028 indicates the decision tree surrogate can approximate the Driverless AI model well. Based on the low RMSE and the fairly high R2 (0.87), we can conclude that this is a somewhat trustworthy surrogate model. By following the decision paths down the decision tree surrogate, we can begin to see details in the Driverless AI model's decision processes. While keeping the discussion above, PAY_1 appears as an import, if not the most crucial feature in the decision tree. PAY_0 is likely the most crucial feature due to its place in the initial split in the tree.
1. To further understand how the decision tree can help us better understand our model, click on one of the terminal nodes. After clicking a terminal node, something similar should appear:
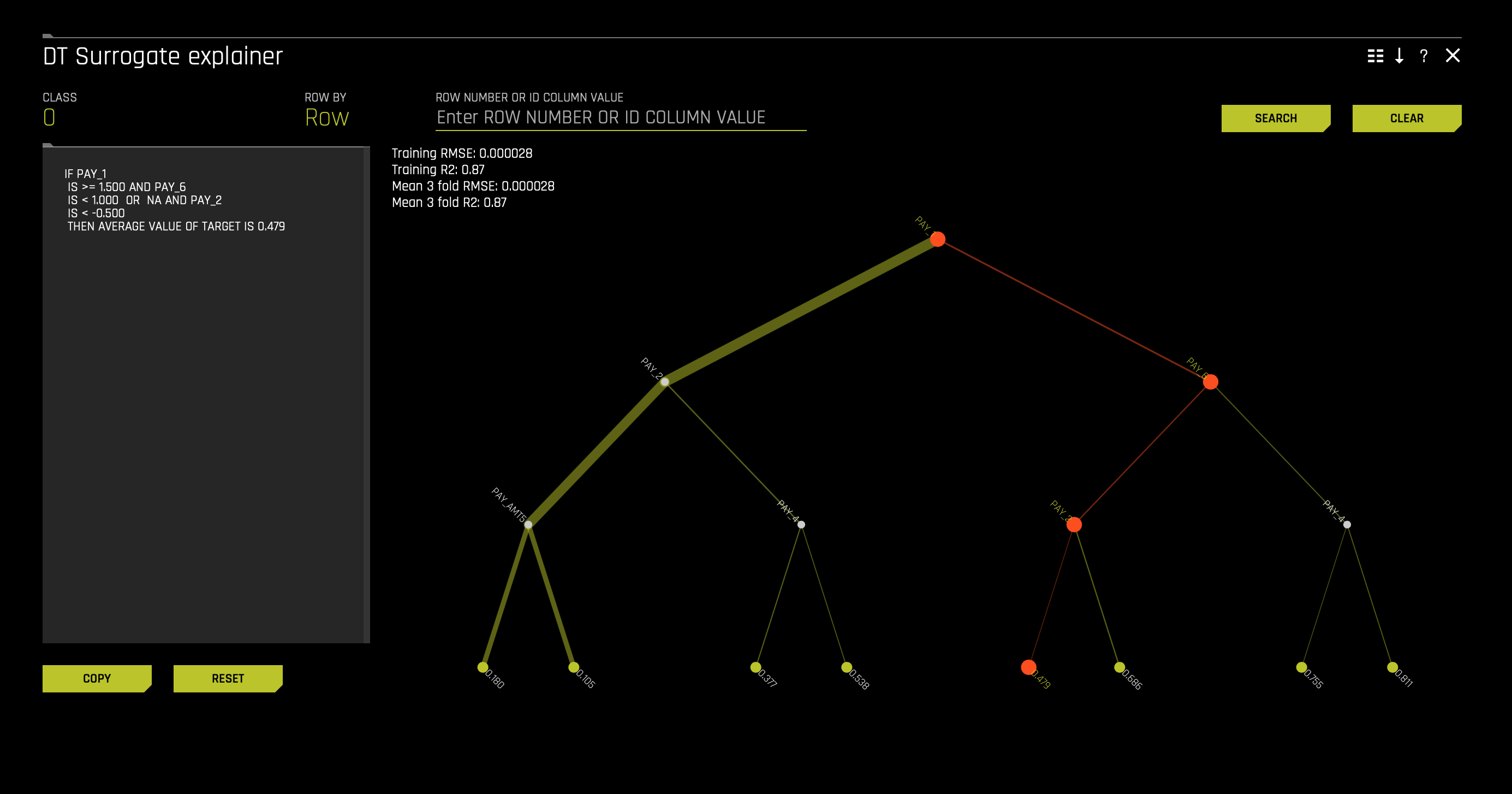
For explanation purposes, terminal node 0.479 has been selected. The selected terminal node is one of the somewhat low probabilities. We end up on terminal node 0.479 as follows:
IF PAY_1
- IS >= 1.500 AND PAY_6
- IS < 1.000 OR NA AND PAY_2
- IS < -0.500
- THEN ABERAGE VALUE OF TARGET IS 0.479
With the above in mind, we see the relevance and importance of PAY_1. According to the rules, if you are above one month late, you are automatically thrown to a side (right) of the tree where high default probabilities lay. As discussed above, being late two months on PAY_1 often leads to high probabilities of default. The second level directs a particular client to terminal node 0.479 if PAY_6 is late less than a month. At last, we end on terminal node 0.479 if the value of PAY_2 = the use of revolving credit.
In terms of how often this path is, we can say that it is not based on the path's thinness. In contrast, the far left paths are most common given the thickness of the paths. And such thick lines happen to be the paths to the lowest default probabilities. As a sanity check, we can say that the surrogate decision tree reveals that the most common predictions are low-default-probabilities. In a way, it makes sense, given that not many people default.
Local Explanations
To conclude our journey on how we can better understand a generated Driverless AI model, we will look at the Dashboard feature. The Dashboard button contains a dashboard with an overview of the interpretations (built using surrogate models). They are located in the upper-right corner.
1. Click the Dashboard button to view the MLI: Explanations page: 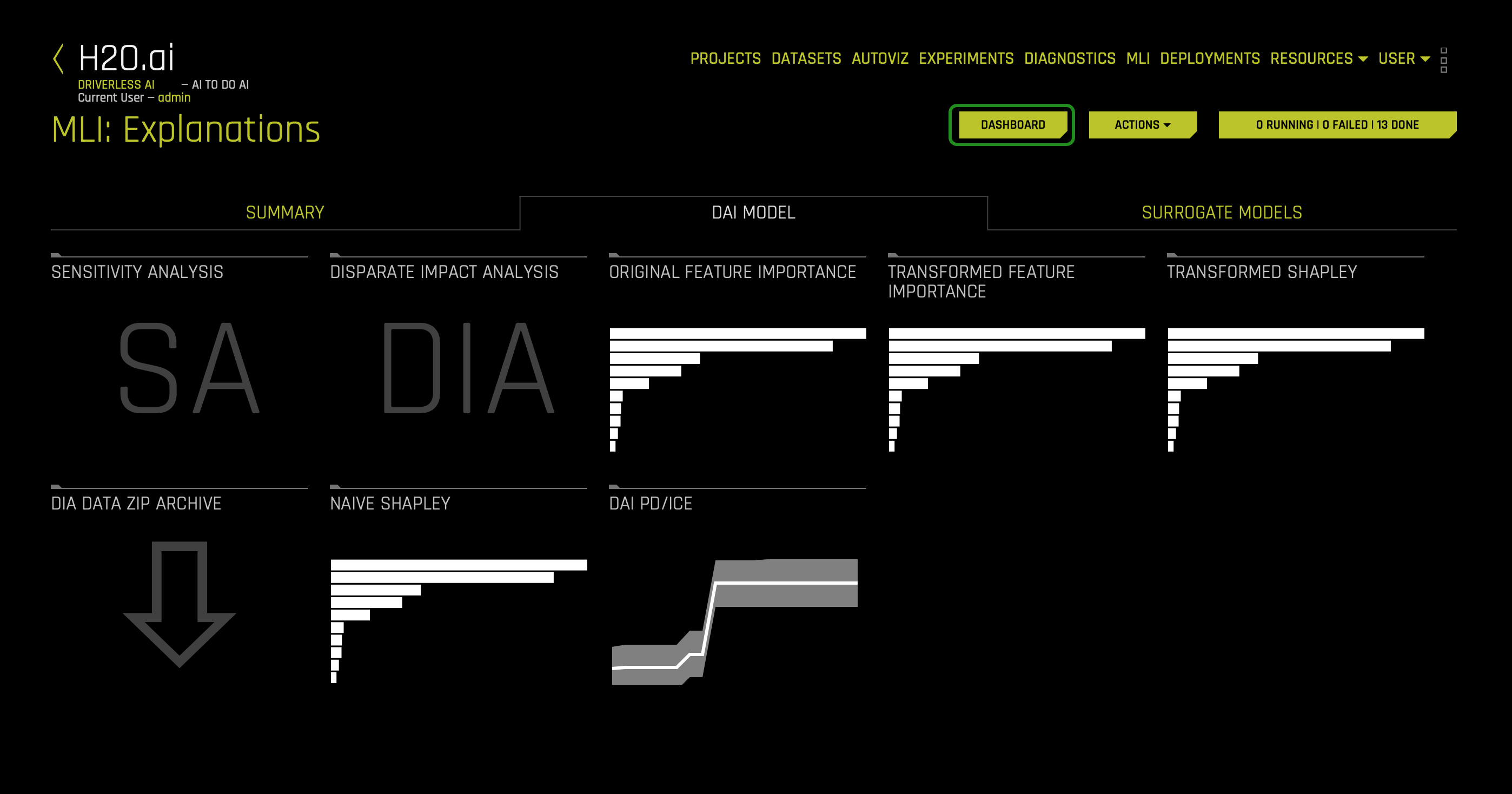
For binary classification and regression experiments, the Dashboard page provides a single page with the following surrogate plots. Note that the PDP and Feature Importance plots on this page are based on the Random Forest surrogate model.
- Global Interpretable Model Explanations
- Feature Importance
- Decision Tree
- Partial Dependence
You can also view explanations from this page by clicking the Explanations button located in the upper-right corner.
Note: The Dashboard is not available for multiclass classification experiments.
2. In the Dashboard in the search bar enter the following ID: 11427. Right after, Click Search. The following will appear:
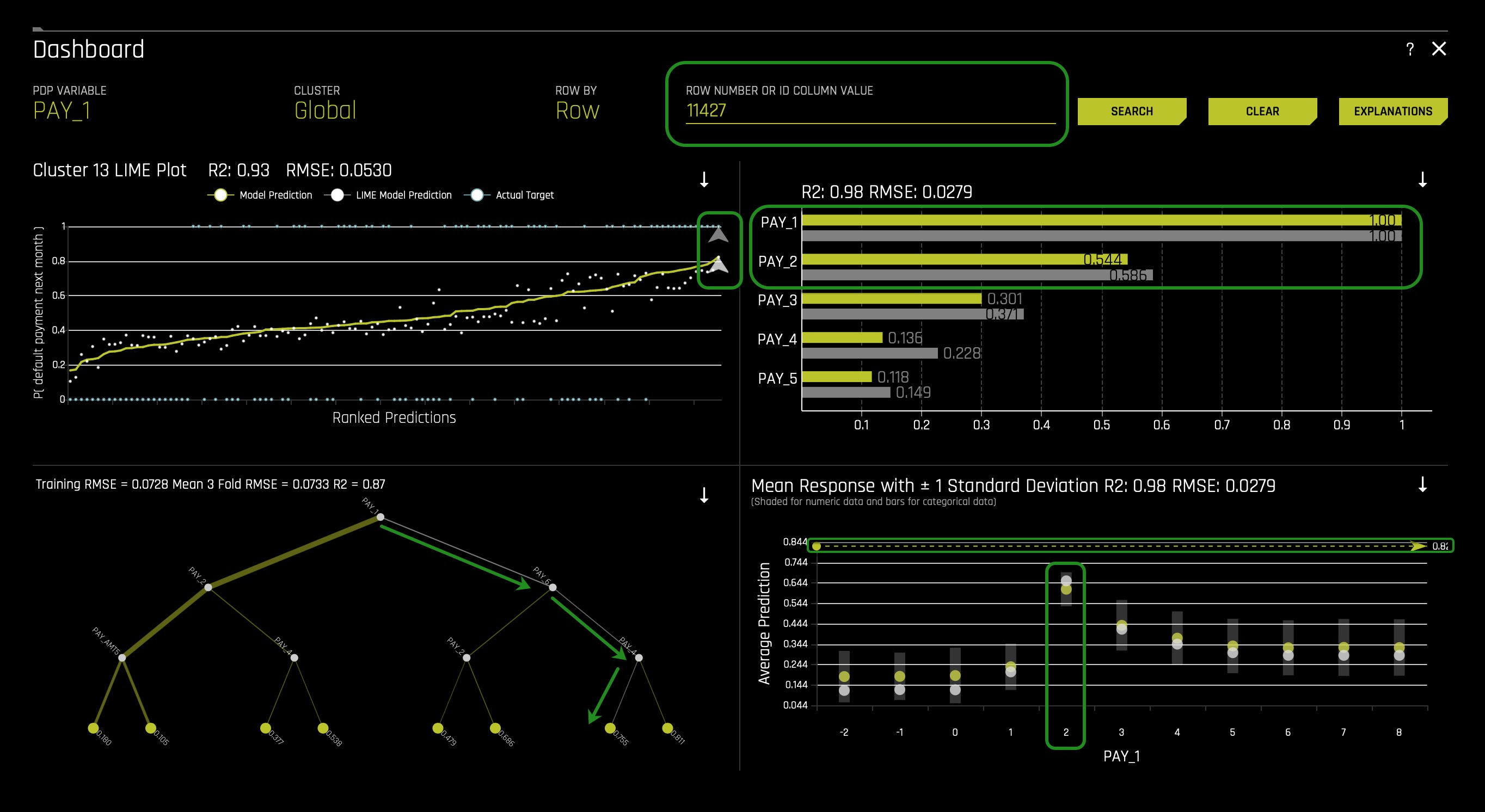
Following the global versus local analysis motif, local contributions to model predictions for a single client are also analyzed and compared to global explanations and reasonable expectations. The above image shows the local dashboard after selecting a single client. For this example use case, a client that actually defaulted is selected.
The above image shows the selected individual's path highlighted in grey in the surrogate decision tree. This selected passenger falls into the node with the second most significant average model prediction for defaulting, which nicely aligns with the Driverless AI model's predicted probability for defaulting of 0.755.
When investigating observations locally, the feature importance has two bars per feature. The upper bar (yellow) represents the global feature importance, and the lower bar (grey) represents the local feature importance. In the image below, the two features PAY_1 and PAY_2 are the most important features both globally and locally for the selected individual.
The local dashboard also overlays ICE curves onto partial dependence plots. In the image above, the lower points for partial dependence remain unchanged from the image above (partial dependence plot) and show the average model prediction by PAY_1. The upper points indicate how the selected client's prediction would change if their value for PAY_1 changed, and the image above indicates the client's prediction for default will decrease dramatically if the value for PAY_1 changed to -1 (paid in full).
If we were to click on the Explanations button on the top right corner of the dashboard, it would tell us the following:
The local English language explanations, or reason codes, from the K-LIME model in the above image parsimoniously indicates that the Driverless AI model's prediction increased for the selected passenger due to the client's value for PAY_1. For the selected passenger, global and local explanations are reasonable when compared to one-another and logical expectations. In practice, explanations for several different types of clients, and especially for outliers and other anomalous observations, should be investigated and analyzed to enhance understanding and trust in the Driverless AI model.
Note: the Dashboard UI allows you to view global, cluster-specific, and local reason codes. You can also export the explanations to CSV.
In general, we can conclude that base on all the observations we have made while using surrogate models to understand the complex Driverless AI model in the original feature space, PAY_1 being two months late results in a high default probability for a given client.
Before we conclude, let's explore the other two tabs on the Model Interpretation page: Summary and DAI (Driverless AI) Model.
Summary Tab
1. On the Model Interpretation page, click the Summary tab, the following will appear:
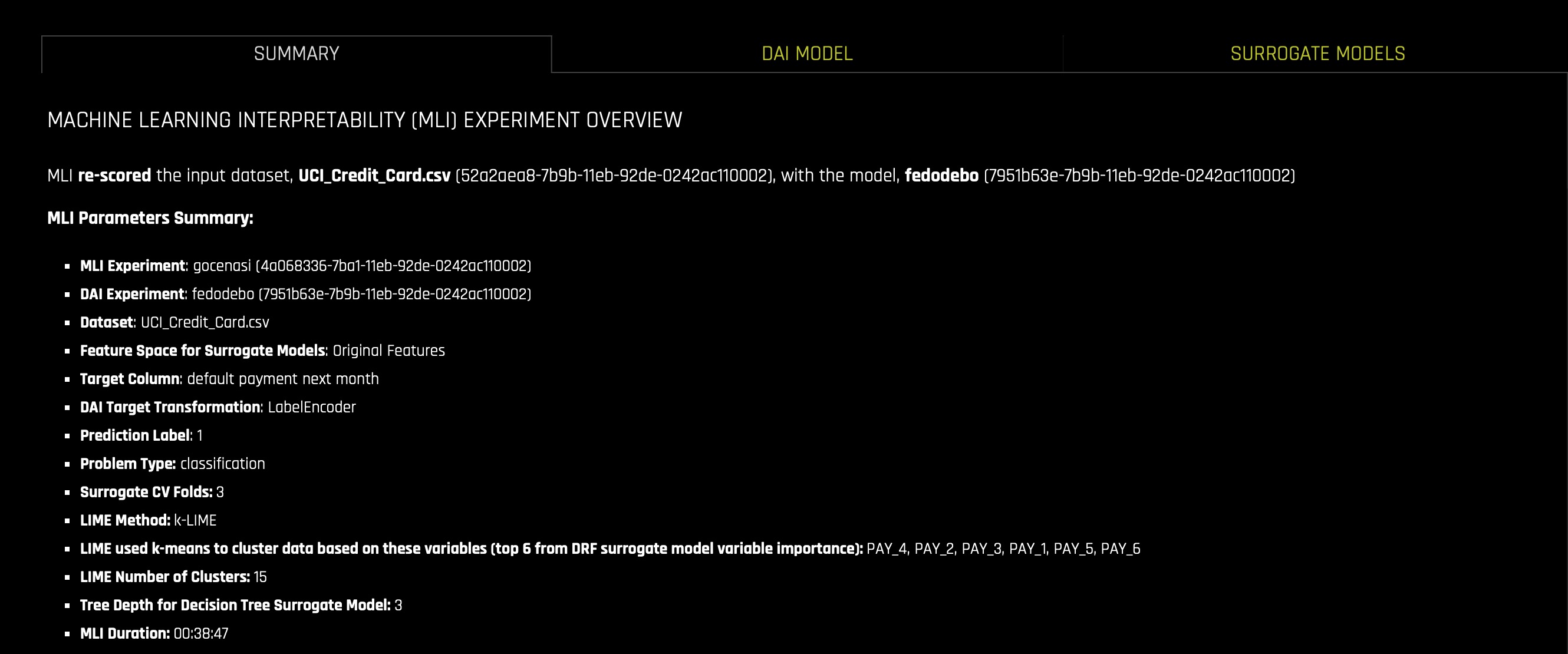
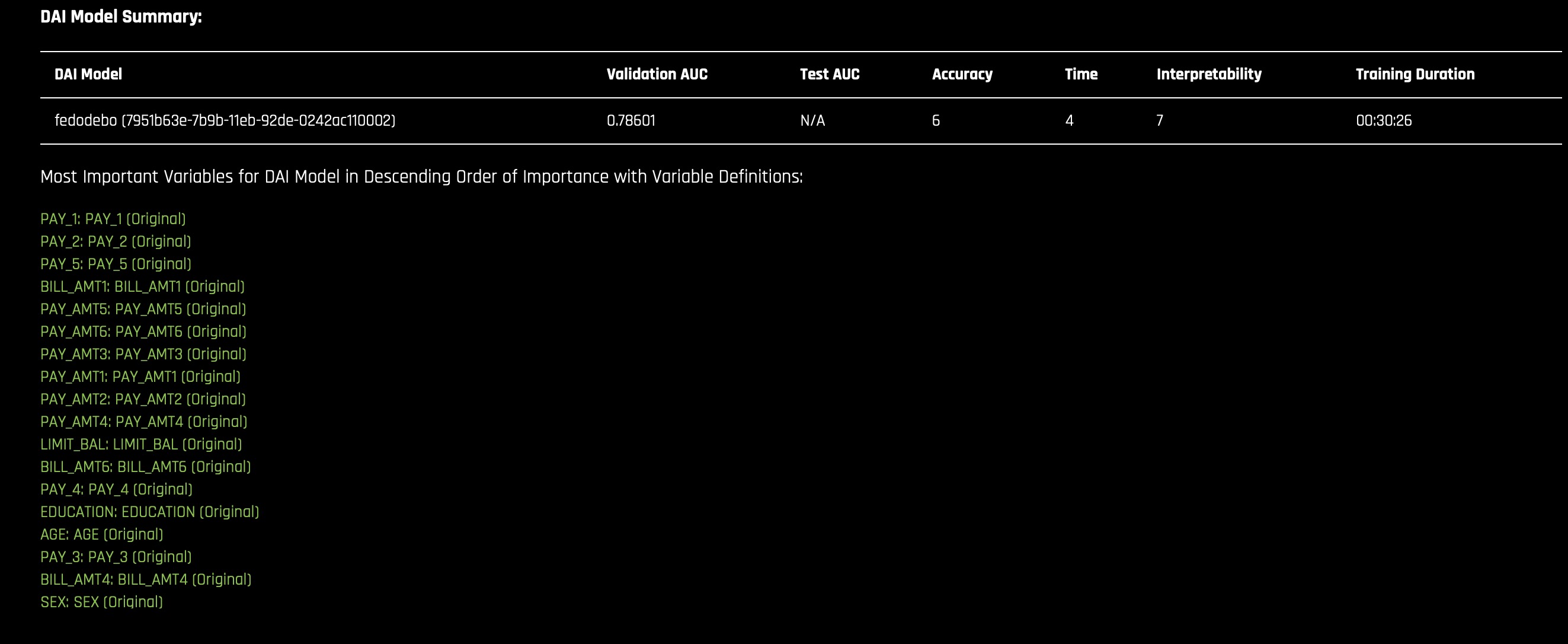


The Summary tab provides an overview of the interpretation, including the dataset and Driverless AI experiment name (if available) that were used for the interpretation along with the feature space (original or transformed), target column, problem type, and k-Lime information. If the interpretation was created from a Driverless AI model, then a table with the Driverless AI model summary is also included along with the top variables for the model.
DAI (Driverless AI) Model
1. On the Model Interpretation page, click the DAI Model tab, the following will appear:
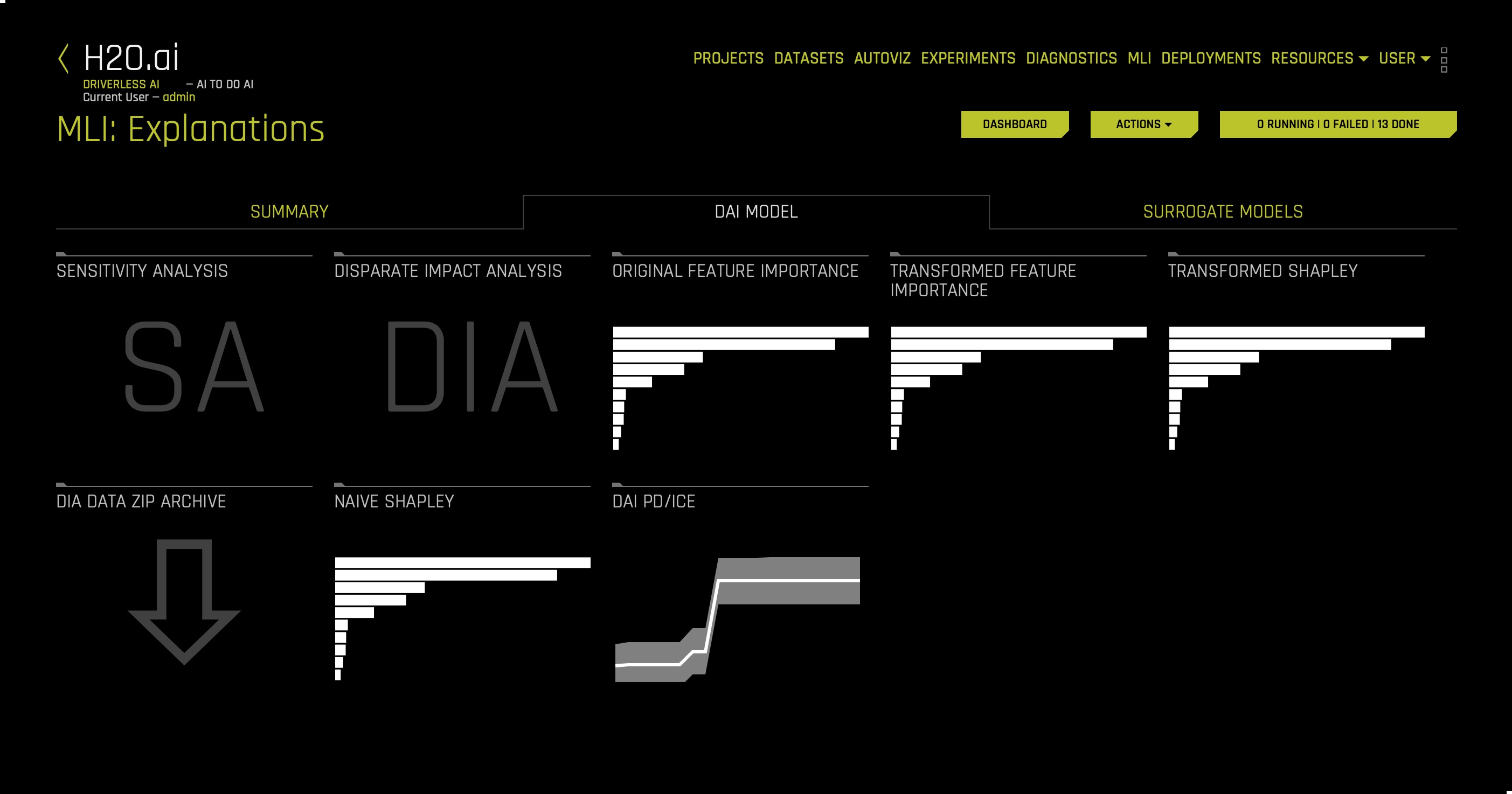
The DAI Model tab is organized into tiles for each interpretation method. To view a specific plot, click the tile for the plot that you want to view.
For binary classification and regression experiments, this tab includes Feature Importance and Shapley (not supported for RuleFit and TensorFlow models) plots for original and transformed features as well as Partial Dependence/ICE, Disparate Impact Analysis (DIA), Sensitivity Analysis, NLP Tokens and NLP LOCO (for text experiments), and Permutation Feature Importance (if the autodoc_include_permutation_feature_importance configuration option is enabled) plots. For multiclass classification experiments, this tab includes Feature Importance and Shapley plots for original and transformed features.
Here is a list of the interpretation plots from the Driverless AI Model:
- Feature Importance (Original and Transformed Features)
- Shapley (Original and Transformed Features)
- Partial Dependence (PDP) and Individual - Conditional Expectation (ICE)
- Disparate Impact Analysis
- Sensitivity Analysis
- NLP LOCO
- Permutation Feature Importance
The plots in the Driverless AI model tab allow you to understand the Driverless AI model. For example, in the Driverless AI tab, we can observe a transformed Shapley plot indicating top transformed features driving model behavior and whether top features positively or negatively impact the model's prediction. Note: these transformed features in the Shapley plot can be complicated to understand. That is why surrogate models offer approximate explanations into what drives the model behavior in the original feature space. Therefore, surrogate models are used to explain the complexity of the developed Driverless AI model.
To learn more about the Summary tab and each plot in the Driverless AI Models tab, click here.
Deeper Dive and Resources
Learn more about Interpretability
- Brief Perspective on Key Terms and Ideas in Responsible AI
- "Towards a rigorous science of interpretable machine learning"
- FAT/ML
- Explainable Artificial Intelligence (XAI)
- H2O K-LIME
- H2O Viewing Explanations
- Global and Local Variable Importance
- H2O Partial Dependency Plot
- H2O Decision Tree Surrogate Model
- On the Art and Science of Machine Learning Explanations
- H2O ICE
Resources and Videos
- H2O Driverless AI Machine Learning Interpretability walkthrough (Oct 18)
- Practical Tips for Interpreting Machine Learning Models - Patrick Hall, H2O.ai (June 18)
- Building Explainable Machine Learning Systems: The Good, the Bad, and the Ugly (May 18)
- Interpretable Machine Learning (April, 17)
- Driverless AI Hands-On Focused on Machine Learning Interpretability - H2O.ai (Dec 17)
- MLI Meetup before Strata NYC 2018
- An Introduction to Machine Learning Interpretability
- Testing machine learning explanation techniques
- Practical techniques for interpretable machine learning
- Patrick Hall and H2O Github
- Awesome-Machine-Learning-Interpretability
- jsm_2018_slides
- mli-resources
- mli-resources
On the Art and Science of Machine Learning Explanations
- Towards A Rigorous Science of Interpretable Machine Learning
- Principles for Accountable Algorithms and a Social Impact Statement for Algorithms
- Explainable Artificial Intelligence (XAI)
- Explainable Artificial Intelligence (XAI)
- Explainable Artificial Intelligence (XAI)
- Broad Agency Announcement Explainable Artificial Intelligence (XAI)
- Explainable Artificial Intelligence (XAI)
Check out the next self-paced course: Time Series - Retail Sales Forecasting, where you will learn more about:
- Time-series:
- Time-series concepts
- Forecasting
- Experiment settings
- Experiment results summary
- Model interpretability
- Analysis