Image processing techniques have become crucial for a diverse range of companies despite their operations over time. In other words, to compete in this global economy, image processing is becoming a requirement for any company hoping to become a credible competitor. Everyone can now see image processing in Agricultural Landscape, Disaster Management, and Biomedical and other Healthcare Applications.
With this in mind, and with the hopes to democratize AI, H2O.ai has automated the processes of obtaining high-quality models capable of image processing.
This self-paced course will explore the two different approaches to modeling images in Driverless AI: Embeddings Transformer (Image Vectorizer) and Automatic Image Model. To lay down the foundations for this self-paced course, we will review transfer learning from pre-trained models. Right after, we will illustrate the first image modeling approach by analyzing a pre-built image model capable of predicting car prices. Directly after, we will better understand the second approach by analyzing a pre-built image model capable of predicting a true case of metastatic cancer. In the final analysis, we will compare and contrast each image modeling approach, and we will discuss several scenarios when a given approach will be better. In particular, and as a point of distinction, we will discuss how the Embeddings Transformer approach only supports a MOJO Scoring Pipeline. Correspondingly, we will discuss how a user can only obtain details about the current best individual model through the Automatic Image Model approach.
All things consider, let us start.
You will need the following to be able to do this self-paced course:
- Basic knowledge of Driverless AI
- Completion of the following two self-paced courses:
- Understanding of Convolutional Neural Networks (CNNs)
- Basic understanding of confusion matrices
- A Two-Hour Test Drive session: Test Drive is H2O.ai's Driverless AI on the AWS Cloud. No need to download software. Explore all the features and benefits of the H2O Automatic Learning Platform.
- Need a Two-Hour Test Drive session? Follow the instructions on this quick self-paced course to get a Test Drive session started.
Note: Aquarium's Driverless AI Test Drive lab has a license key built-in, so you don't need to request one to use it. Each Driverless AI Test Drive instance will be available to you for two hours, after which it will terminate. No work will be saved. If you need more time to explore Driverless AI further, you can always launch another Test Drive instance or reach out to our sales team via the contact us form.
As mentioned in the objective section, we will use three image models, but running each experiment takes time to run. For this reason, all experiments have been built for you and can be found in Driverless AI's Experiments section:
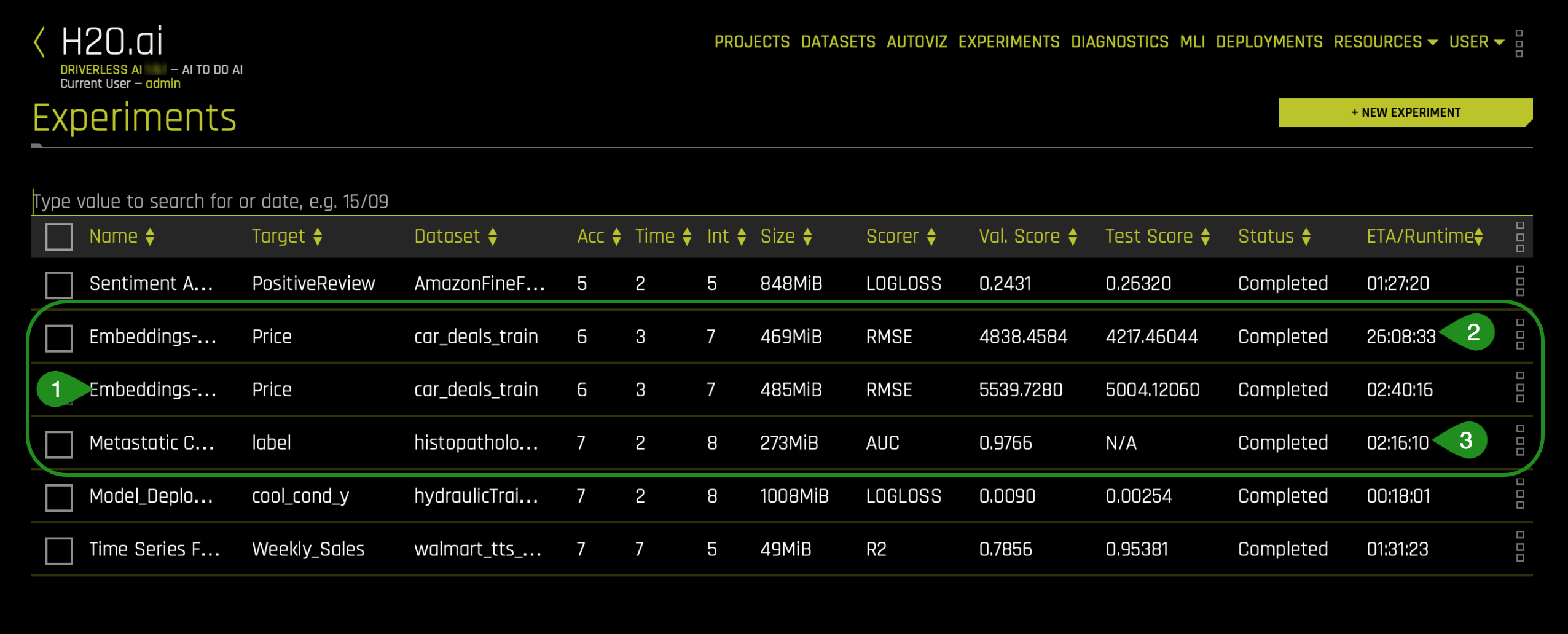
- Model 1: Embeddings-Transformer-Without-Fine-Tuning
- Model 2: Embeddings-Transformer-With-Fine-Tuning
- Model 3: Metastatic Cancer - Automatic Image Model
For understanding purposes, let's see how the first experiment was run. Right after, we will follow to understand the dataset and settings used in the first image model; doing so will allow us to understand embeddings Transformer (the first approach to image processing in Driverless AI).
Our first image model (experiment) predicts a car's price (again, we will explore the dataset and all settings for this model in a moment).
If you were to run the experiment, you would take the following steps:
On the Datasets page, import the Kaggle-MyAutoData-dataset:
- Click + ADD DATASET (OR DRAG & DROP)
- Click the AMAZON S3 option
- In the search bar, paste the following s3 URL: s3://h2o-public-test-data/bigdata/server/ImageData/car_deals.zip
- Before pasting clear anything that might be in the search bar
- Select the following option: car_deals.zip [776.5MB]

- CLICK TO IMPORT SELECTION
- After the dataset is imported successfully, the new dataset will be under the following name: car_deals.zip
On the Datasets page:
- Click the following dataset: car_deals.zip
- Click SPLIT
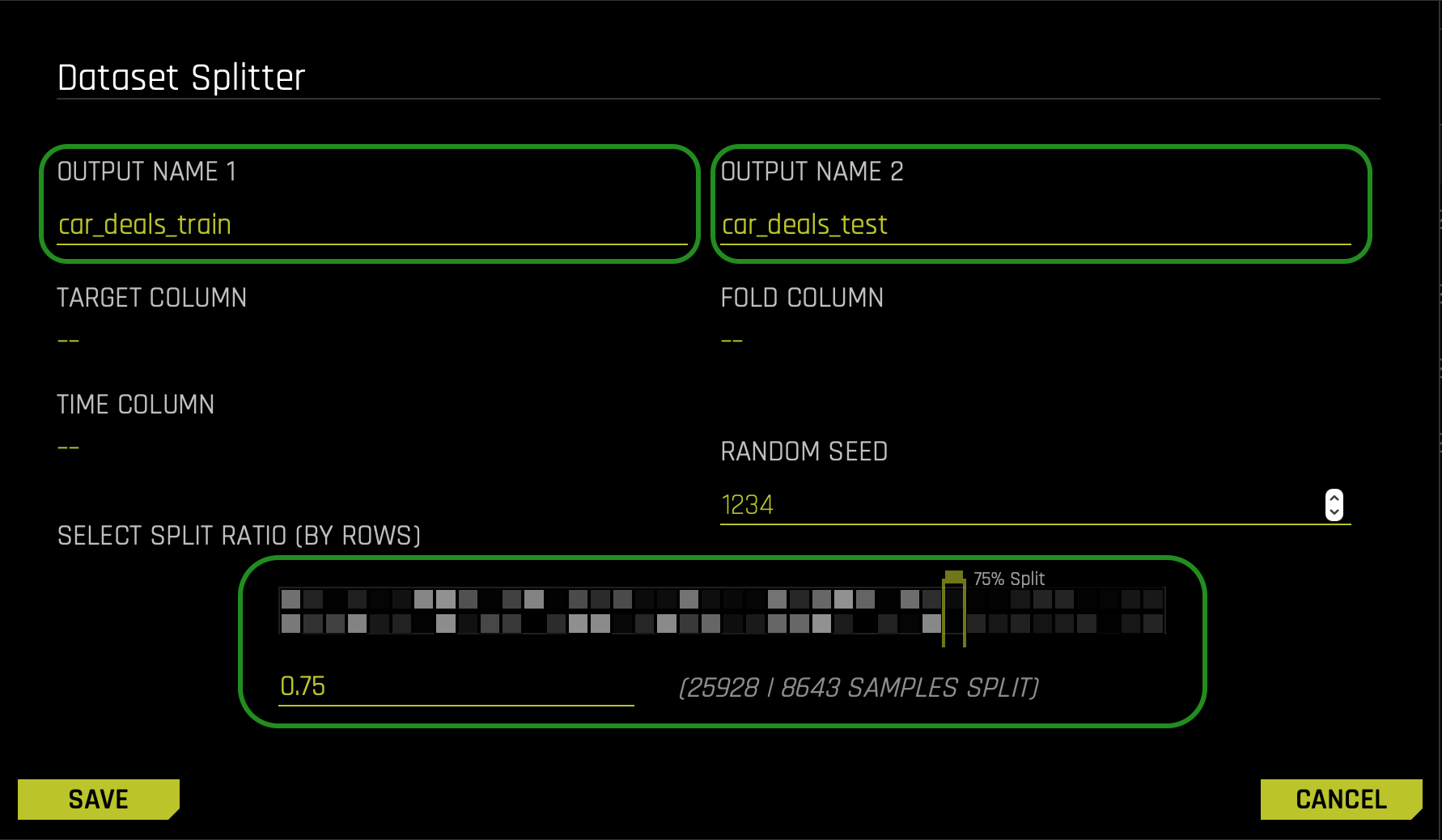
Split the dataset into two sets:
- Name OUTPUT NAME 1 as follows: car_deals_train
- Name OUTPUT NAME 2 as follows: car_deals_test
- Change the split value to
.75by adjusting the slider to75%or entering.75in the section that says SELECT SPLIT RATIO(BY ROWS) - SAVE
Now, you should see the following two new datasets in the Datasets Page:
- car_deals_train
- car_deals_test
On the Datasets page:
- Click the following dataset: car_deals_train
- Click PREDICT
- First time using Driverless AI? Click Yes to get a tour! Otherwise, click No
- Name your experiment
Embeddings-Transformer-Without-Fine-Tuning - For the TEST DATASET select the following dataset: car_deals_test
- As a target column, select Price
Now let's drop few columns:
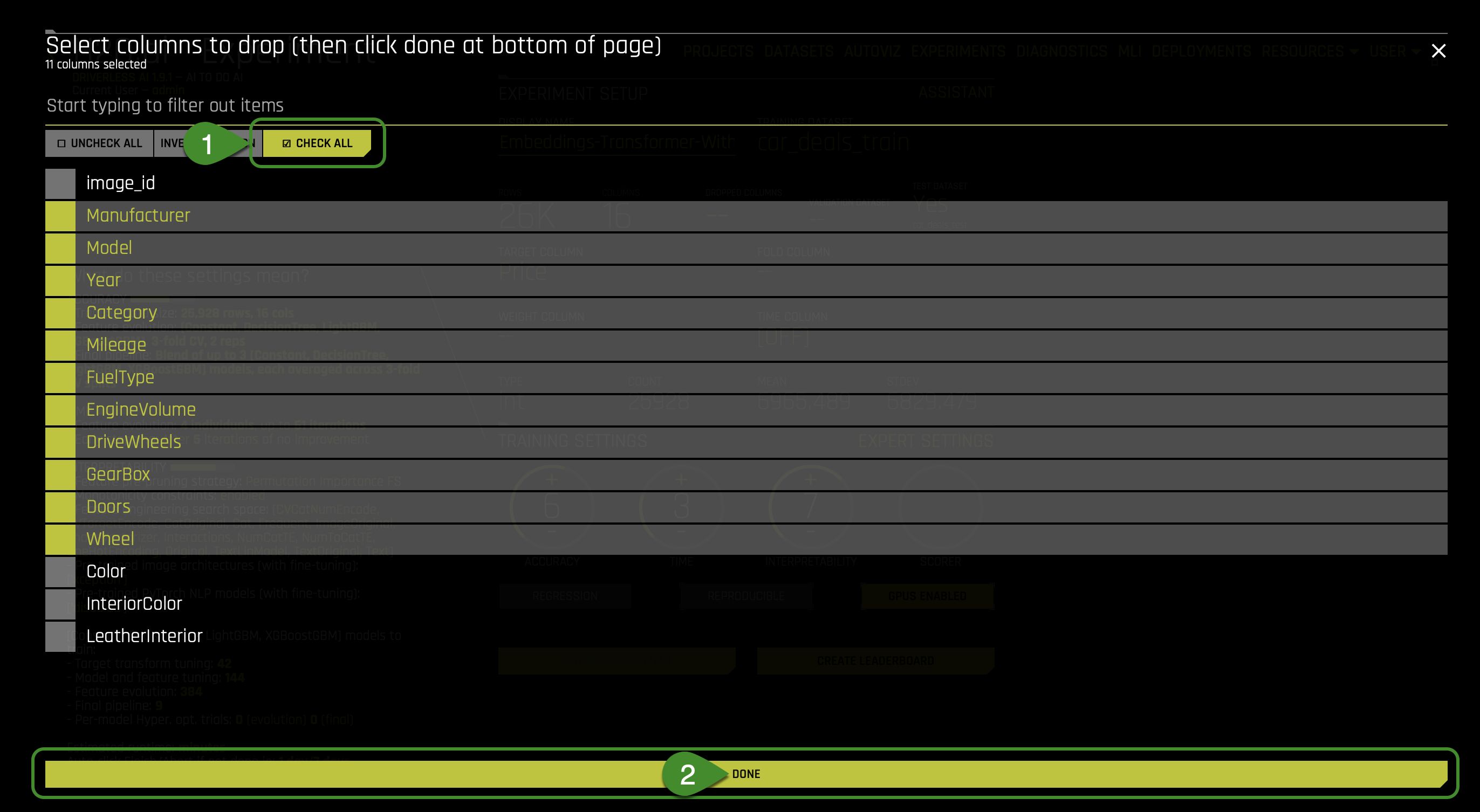
Click the DROPPED COLUMNS option:
- Click the CHECK ALL option:
- Deselect the following columns:
- image_id
- Color
- InteriorColor
- Leatherinterior
- Deselect the following columns:
- Click Done
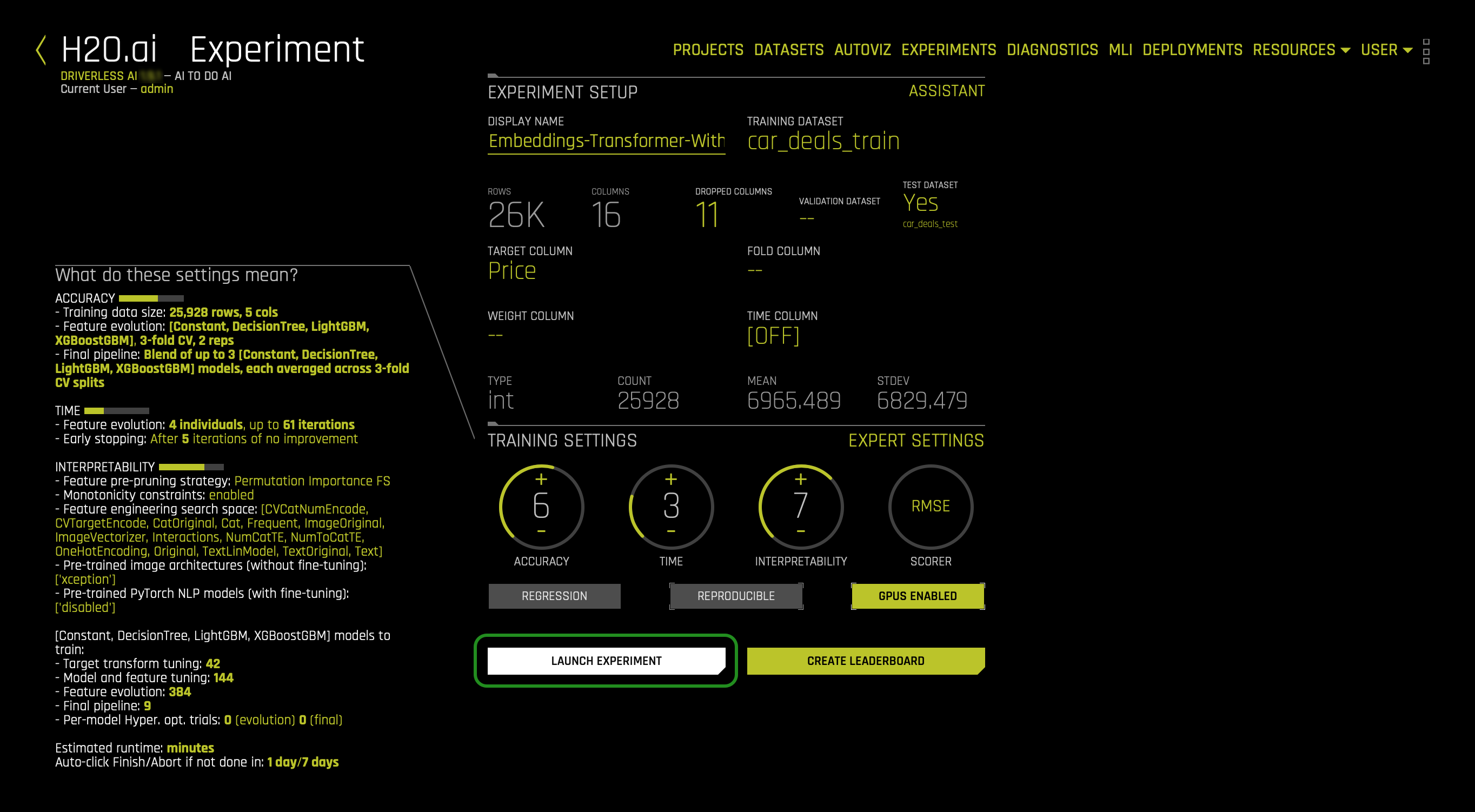
LAUNCH EXPERIMENT:
Before we further explore the dataset and settings used in the first image model, let's discuss transfer learning concepts from pre-trained models. Those concepts that will help us understand Embeddings Transformer (Image Vectorizer).
In image classification, the goal is to classify an image based on a set of possible categories. In general, classifying images is a bit hard, but such a difficulty can find ease in transfer learning.
Transfer learning allows anyone to build accurate models that make building image models less difficult. Transfer Learning allows you to avoid relearning certain patterns again because you can use patterns others learned when solving another problem. Transfer Learning prevents many from starting from scratch.
- "In computer vision, transfer learning is usually expressed through the use of pre-trained models. A pre-trained model is a model that was trained on a large benchmark dataset to solve a problem similar to the one that we want to solve. Accordingly, due to the computational cost of training such models, it is common practice to import and use models from published literature (e.g. VGG, Inception, MobileNet)" (Pedro Marcelino).
For the most part, pre-trained models used in transfer learning are based on large Convolutional Neural Networks (CNNs). Why? Because CNN's have express high performance and easiness in training. In neural networks, CNNs have become essential to the process of face recognition and object detection. In layman's terms, a CNN can take an input image, process it, and classify it under certain categories (Eg., Snake, Cat, Dog, Monkey).
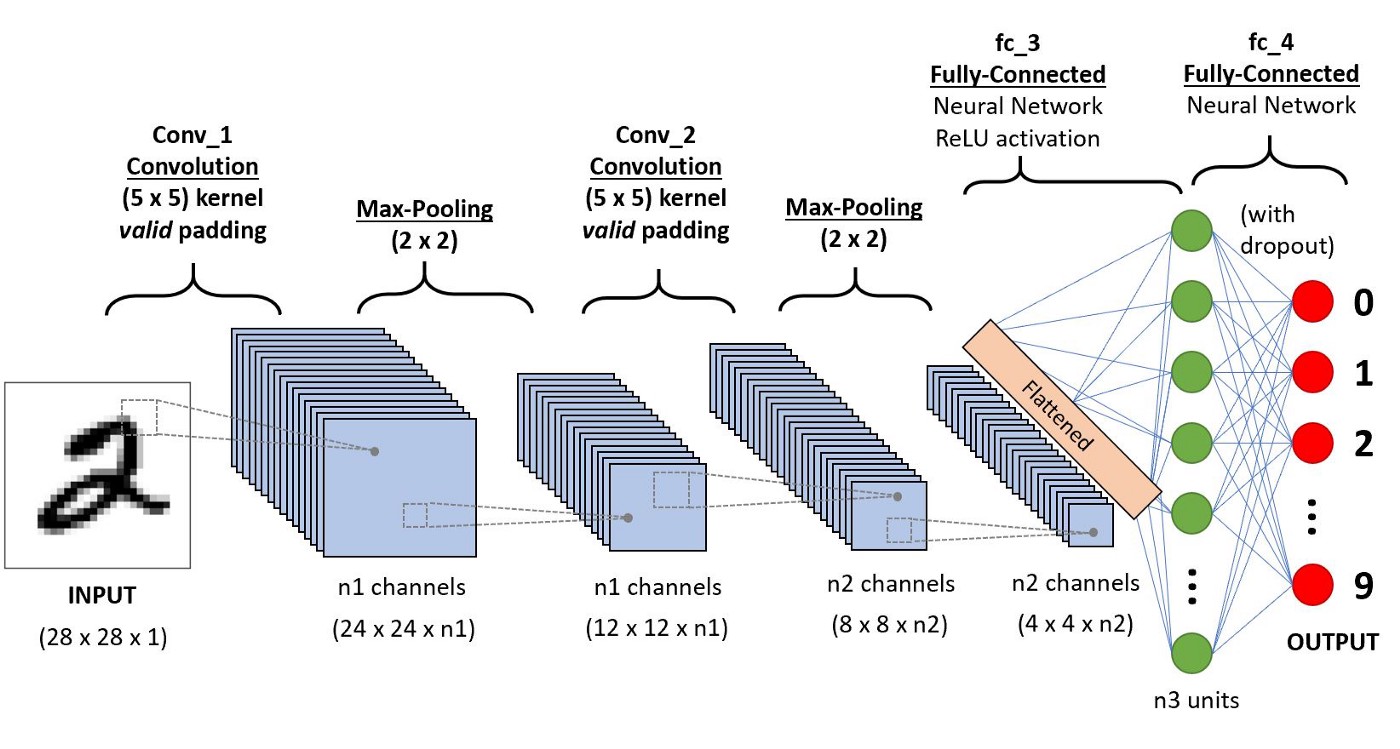
Figure 1. CNN Overview One
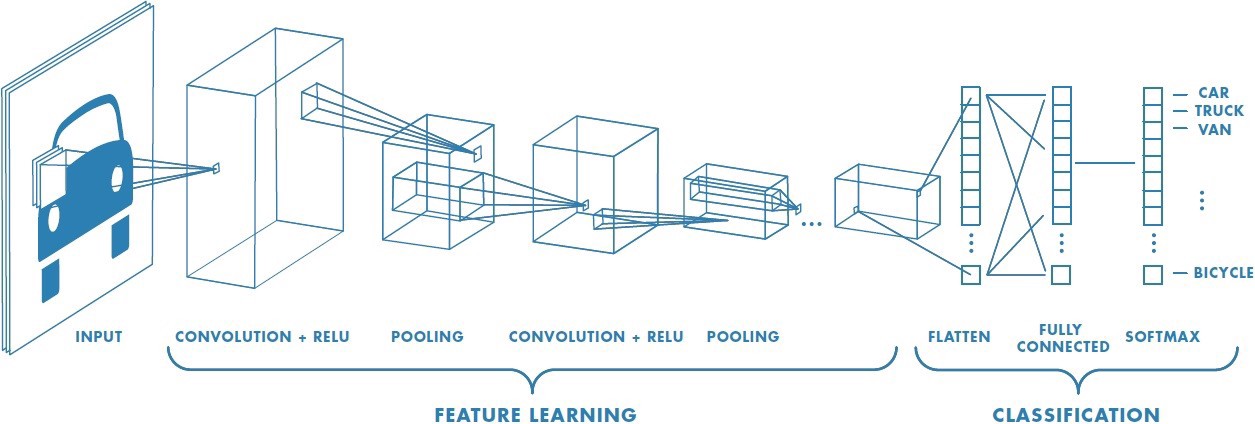
Figure 2. CNN Overview Two
A typical CNN has two parts:
- A Convolutional Base is structured by a stack of convolutional and pooling layers, and the goal of this stack is to generate features from the image (input).
- A Classifier is formed by fully connected layers which classify the input image based on the convolutional base's features. The Classifier's goal is to classify the image based on the detected features.
The following image shows the architecture of a model based on CNNs. It is important to note that this illustration is a simplified version that fits this self-paced course's purposes (the illustration doesn't capture the complexity of the model's architecture).
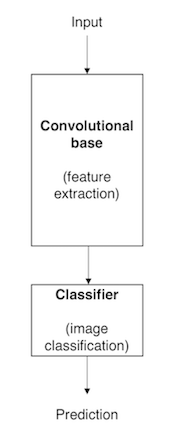
Figure 3. Architecture of a model based on CNNs
When you are remodeling a pre-trained model for your tasks, you begin by removing the original Classifier, then you add a new classifier that fits your purposes, and lastly, you fine-tune your model according to one of three strategies:
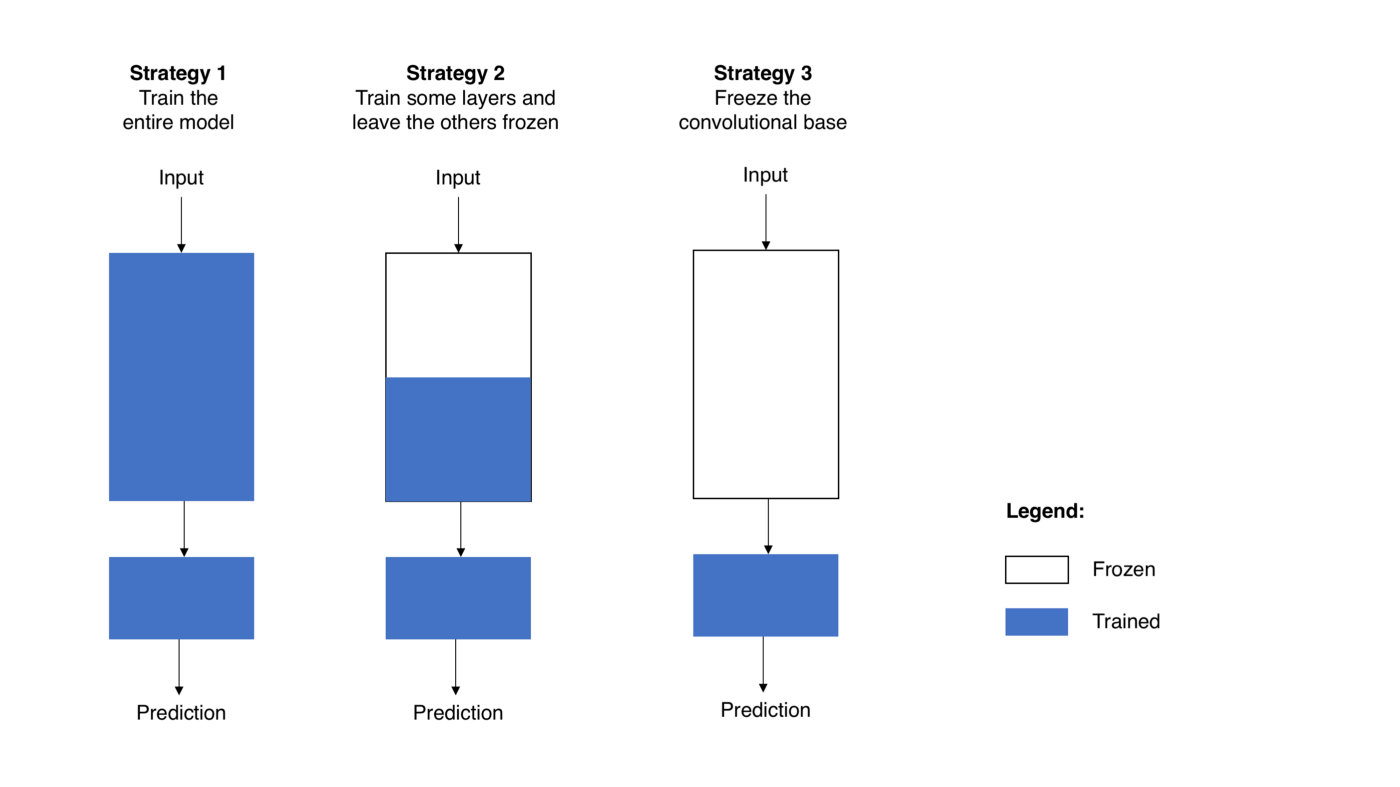
Figure 4. strategies
- Stradegy 1: "Train the entire model. In this case, you use the architecture of the pre-trained model and train it according to your dataset. You're learning the model from scratch, so you'll need a large dataset (and a lot of computational power)"(Pedro Marcelino).
- Stradegy 2: "Train some layers and leave the others frozen. [L]ower layers refer to general features (problem independent), while higher layers refer to specific features (problem dependent). Here, we play with that dichotomy by choosing how much we want to adjust the weights of the network (a frozen layer does not change during training). Usually, if you've a small dataset and a large number of parameters, you'll leave more layers frozen to avoid overfitting. By contrast, if the dataset is large and the number of parameters is small, you can improve your model by training more layers to the new task since overfitting is not an issue"(Pedro Marcelino).
- Stradegy 3: "Freeze the convolutional base. This case corresponds to an extreme situation of the train/freeze trade-off. The main idea is to keep the convolutional base in its original form and then use its outputs to feed the classifier. You're using the pre-trained model as a fixed feature extraction mechanism, which can be useful if you're short on computational power, your dataset is small, and/or pre-trained model solves a problem very similar to the one you want to solve"(Pedro Marcelino).
Accordingly and from a practical perspective, the process of transfer learning can be summed up as follows:
- Select a pre-trained model
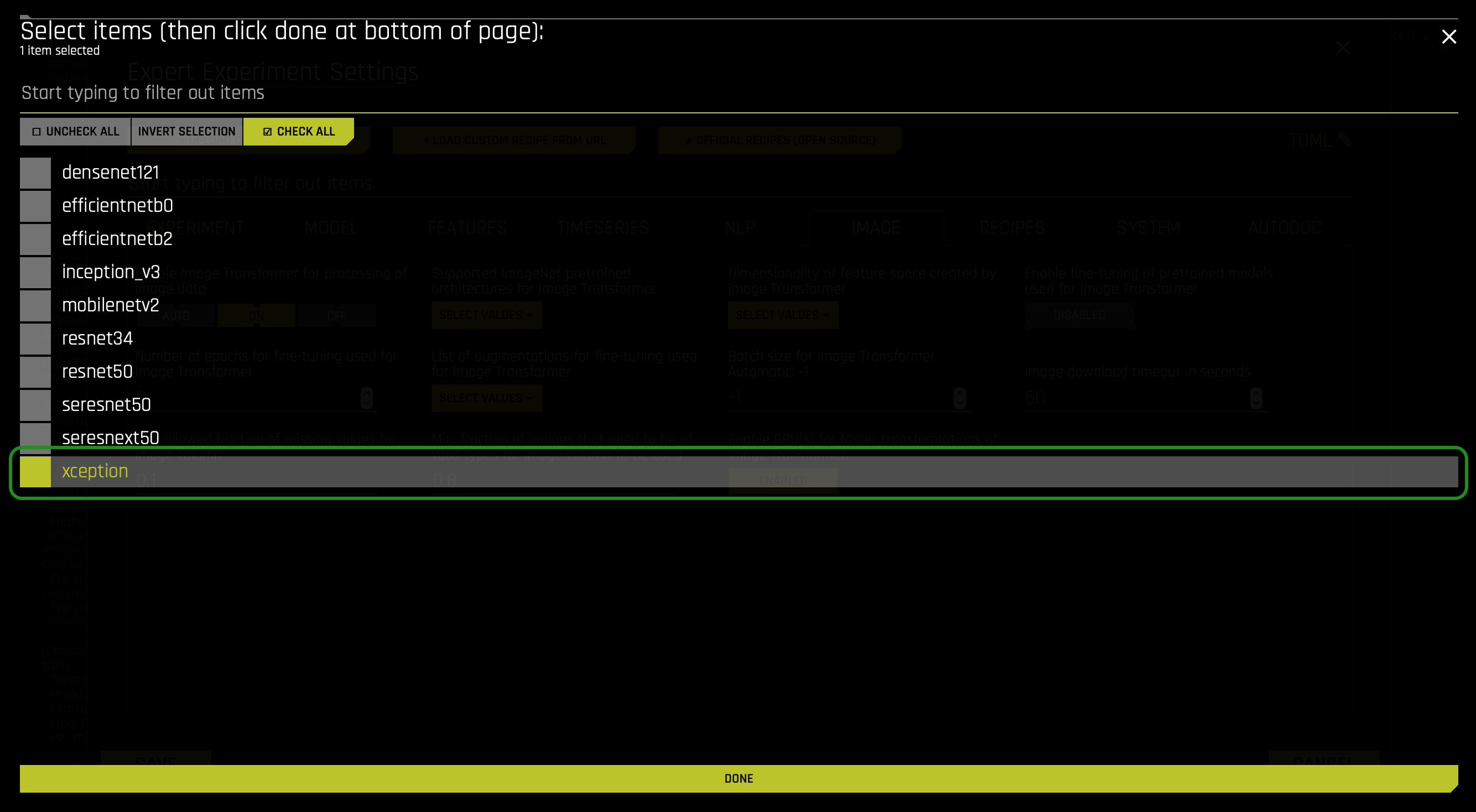
When it comes to selecting a pre-trained model - you pick one that looks suitable for your problem. Note, in Driverless AI you have access to the following set of pre-trained ImageNet models:
- densenet121
- efficientnetb0
- efficientnetb2
- inception_v3
- mobilenetv2
- resnet34
- resnet50
- seresnet50
- seresnext50
- xception (Selected by default)
The above pre-trained ImagNet Models (CNN architectures), also know as Convolutional Neural Networks, have been pre-trained on the ImageNet dataset.
ImageNet is a project that aims to label and categorize images into almost 22,000 separate object categories. Through the categorization and labeling of images, ImageNet hopes to make the ImageNet dataset a useful resource for educators, students, and the mission of computer vision research. In the world of deep learning and Convolutional Neural Networks, people often refer to the ImageNet Large Scale Visual Recognition Challenge when the term "ImageNet" is mentioned. "The goal of this image classification challenge is to train a model that can correctly classify an input image into 1,000 separate object categories. Models are trained on ~1.2 million training images with another 50,000 images for validation and 100,000 images for testing. These 1,000 image categories represent object classes that we encounter in our day-to-day lives, such as species of dogs, cats, various household objects, vehicle types, and much more"(Adrian Rosebrock).
The ImageNet challenge is now leading in the realm of image classification. This challenge has been dominated by Convolutional Neural Networks and deep learning techniques. Right now, several networks exist that represent some of the highest performing Convolutional Neural Networks on the ImageNet challenge. These networks also demonstrate a strong ability to generalize images outside the ImageNet dataset via transfer learning, such as feature extraction and fine-tuning. That is why Driverless AI can use the mentioned network architectures above because of their fine-tuning and feature extraction ability.
- Classify your problem according to the Size-Similarity Matrix
In the following image, you have ‘The Matrix' that controls your choices regarding classifying your problem according to the Size-Similarity Matrix.
This matrix classifies your computer vision problem considering [your dataset's size] and its similarity to the dataset in which your pre-trained model was trained. [Note that] as a rule of thumb, [a dataset is small if it has less than 1000 images per class]. Regarding dataset similarity, common sense should prevail. For example, if your task is to identify cats and dogs, ImageNet (an image database) would be a similar dataset because it has images of cats and dogs. However, if your task is to identify cancer cells, ImageNet can't be considered a similar dataset.
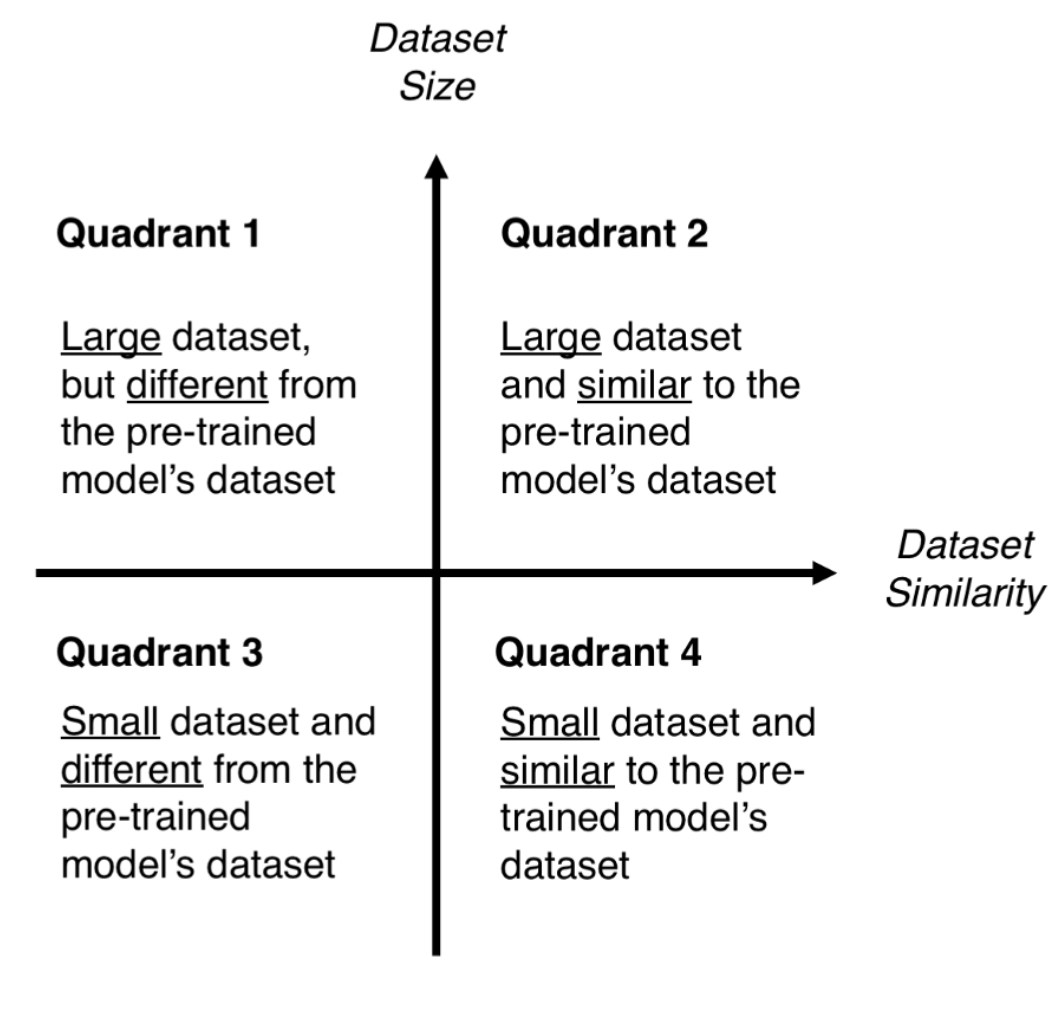
Figure 5. Quadrants
- Fine-tune your model
Here you can use the Size-Similarity Matrix to oversee your selection and then refer to the three alternatives we mentioned before about remodeling a pre-trained model. The following image provides a visual summary of the text that follows:
- Quadrant 1. "Large dataset, but different from the pre-trained model's dataset. This situation will lead you to Strategy 1. Since you have a large dataset, you're able to train a model from scratch and do whatever you want. Despite the dataset dissimilarity, in practice, it can still be useful to initialise your model from a pre-trained model, using its architecture and weights"(Pedro Marcelino).
- Quadrant 2. "Large dataset and similar to the pre-trained model's dataset. Here you're in la-la land. Any option works. Probably, the most efficient option is Strategy 2. Since we have a large dataset, overfitting shouldn't be an issue, so we can learn as much as we want. However, since the datasets are similar, we can save ourselves from a huge training effort by leveraging previous knowledge. Therefore, it should be enough to train the classifier and the top layers of the convolutional base"(Pedro Marcelino).
- Quadrant 3. "Small dataset and different from the pre-trained model's dataset. This is the 2–7 off-suit hand of computer vision problems. Everything is against you. If complaining is not an option, the only hope you have is Strategy 2. It will be hard to find a balance between the number of layers to train and freeze. If you go to deep your model can overfit, if you stay in the shallow end of your model you won't learn anything useful. Probably, you'll need to go deeper than in Quadrant 2 and you'll need to consider data augmentation techniques"(Pedro Marcelino).
- Quadrant 4. "Small dataset, but similar to the pre-trained model's dataset. [For this situation, Strategy 3 will work best.] You just need to remove the last fully-connected layer (output layer), run the pre-trained model as a fixed feature extractor, and then use the resulting features to train a new classifier"(Pedro Marcelino).
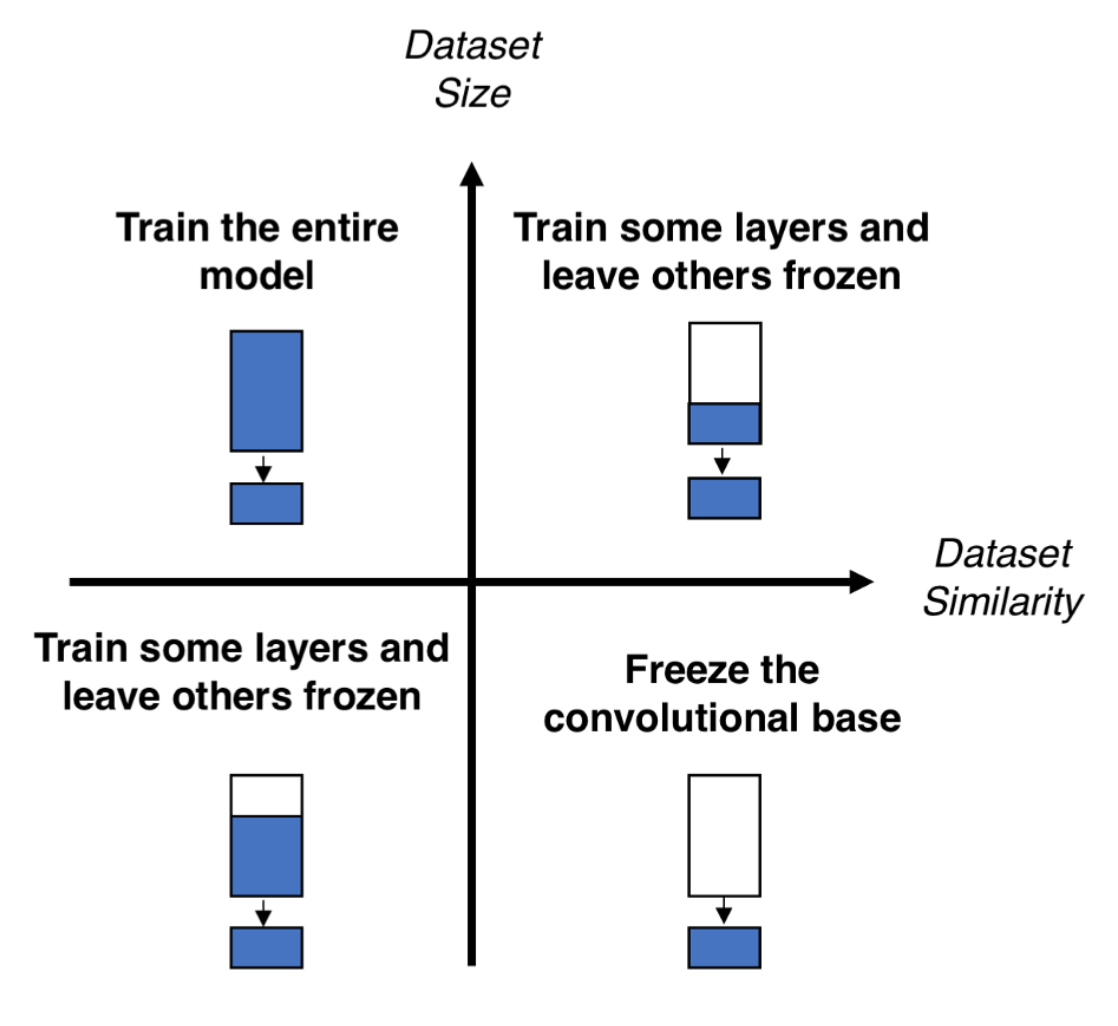
Figure 6. Quadrants + Strategies
As noted above, models for image classification that result from a transfer learning approach based on pre-trained convolutional neural networks are usually composed of two parts. When it comes to the Classifier one can follow several approaches when building the Classifier. For example:
- Global Average Pooling: "In this approach, instead of adding fully connected layers on top of the convolutional base, we add a global average pooling layer and feed its output directly into the softmax activated layer"(Pedro Marcelino).
Other approaches include Fully-connected layers and Linear support vector machines.
When it comes to image classification, you don't have to use the transfer learning technique. Therefore, what are the advantages of using transfer learning?
- Transfer Learning brings already a certain amount of performance before any training occurs.
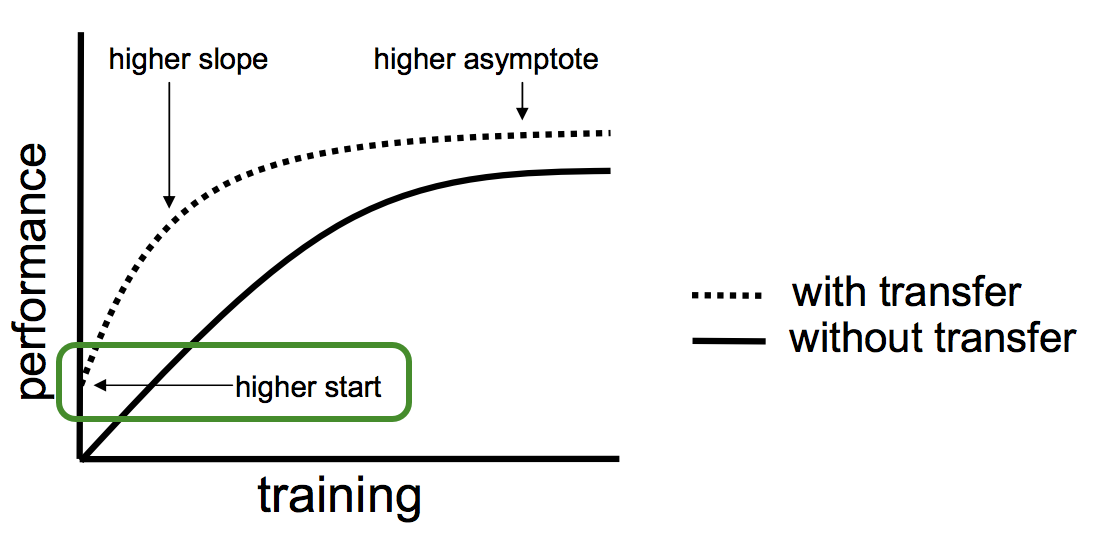
Figure 7. Transfer Learning
- Transfer learning leads to generalization where the model is prepared to perform well with data it was not trained on.
With this task in mind, let us now understand the dataset and settings used in the first experiment; doing so will allow us to understand Embeddings Transformer (the first approach to image processing in Driverless AI).
References
- Marcelino, Pedro. "Transfer Learning from Pre-Trained Models." Medium, Towards Data Science, 23 Oct. 2018, towardsdatascience.com/transfer-learning-from-pre-trained-models-f2393f124751.
- Rosebrock, Adrian. "ImageNet: VGGNet, ResNet, Inception, and Xception with Keras." Py Image Search, 20 March. 2017, pyimagesearch.com/2017/03/20/imagenet-vggnet-resnet-inception-xception-keras/.
- Figure 1. CNN Overview One
- Figure 2. CNN Overview Two
- Figure 3. Architecture of a model based on CNNs
- Figure 4. strategies
- Figure 5. Quadrants
- Figure 6. Quadrants + Strategies
- Figure 7. Transfer Learning
Embeddings Transformer (Image Vectorizer) without Fine-tuning
Embeddings Transformer (Image Vectorizer) is the first approach to modeling images in Driverless AI. The Image Vectorizer transformer utilizes pre-trained ImageNet models to convert a column with an image path or URI ((Uniform Resource Identifier)) to an embeddings (vector) representation that is derived from the last global average pooling layer of the model. The resulting vector is then used for modeling in Driverless AI. This approach can be use with and without fine-tuning. In a moment, we will further explore the difference between with and without fine-tuning.
Notes:
- Transformer refers to the Driverless AI internal terms (e.g., like a target-encoding transformer for tabular data). To learn more about Driverless AI Transformations, please refer to this documentation
- This modeling approach supports classification and regression experiments
In Driverless AI, there are several options in the Expert Settings panel that allow you to configure the Image Vectorizer transformer. While building the first experiment, note that we never configure the Image Vectorizer transformer. The reason being, when Driverless AI detected an image column in our dataset, certain default settings were used for our experiment. To bring the above into a clearer perspective, let us review how we ran our first experiment in task one while understaing a bit more about Embeddings Transformer .
Note: we will only discuss the settings relevant to this self-paced course.
First, let's briefly discuss the multiple methods Driverless AI supports for uploading image datasets:
- Archive with images in directories for each class. Labels for each class are created based on the directory hierarchy
- Archive with images and a CSV file that contains at least one column with relative image paths and a target column(best method for regression)
- CSV file with local paths to the images on the disk
- CSV file with remote URLs to the images
Now let's focus on the dataset used for the first experiment:
- In the Datasets page click the car_deals_train dataset
- Click the DETAILS options
- In the dataset details page, click the following button located at the top right corner of the page: DATASET ROWS
The following should appear:
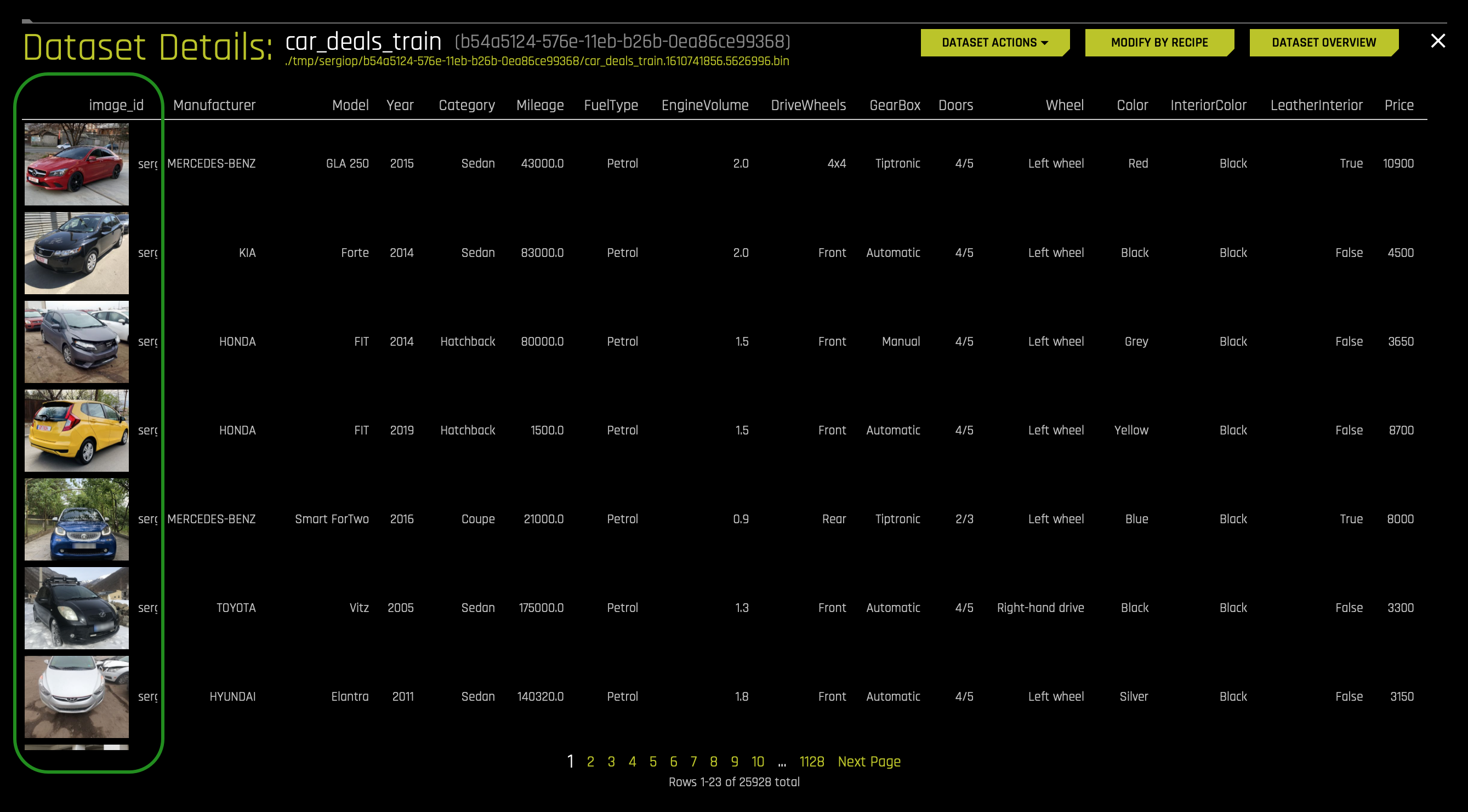
When looking at the dataset rows, we will notice that our dataset has columns with different data types. That is because this modeling approach (Embeddings Transformer) supports the use of mixed data types (any number of image columns, text columns, numeric or categorical columns).
In the first column (image_id), you will see images. When we predicted on the car_deals_train dataset, Driverless AI detected the images, and in the EXPERIMENT PREVIEW page, it decided to enable the Image Transformer setting (as observed in the image below). In other words, Driverless AI enabled the Image Transformer for the processing of image data. Driverless AI uses Image Transformer (first approach) by default if there is at least a single image column in the dataset. In a moment, we will discuss how we can tell Driverless AI to use the second approach to image processing.
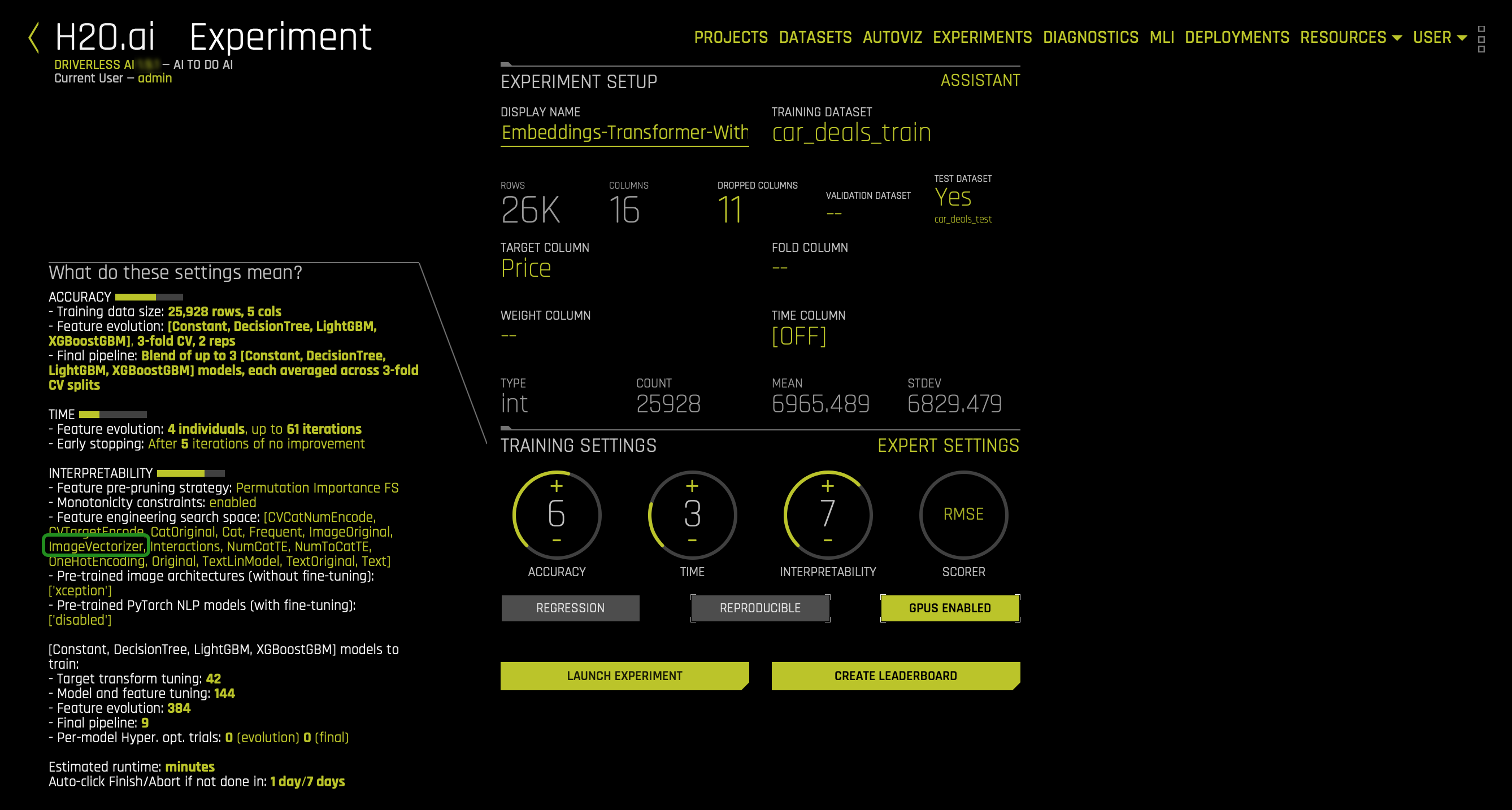
Note that in the Image tab inside the EXPERT SETTINGS, you can Enable Image Transformer for processing of image data:
To rephrase it, you can specify whether to use pre-trained deep learning models to process image data as part of the feature engineering pipeline. When this is enabled, a column of Uniform Resources Identifiers (URIs) to images is converted to a numeric representation using ImageNet pre-trained deep learning models. Again, the Image Transformer is enabled by default.
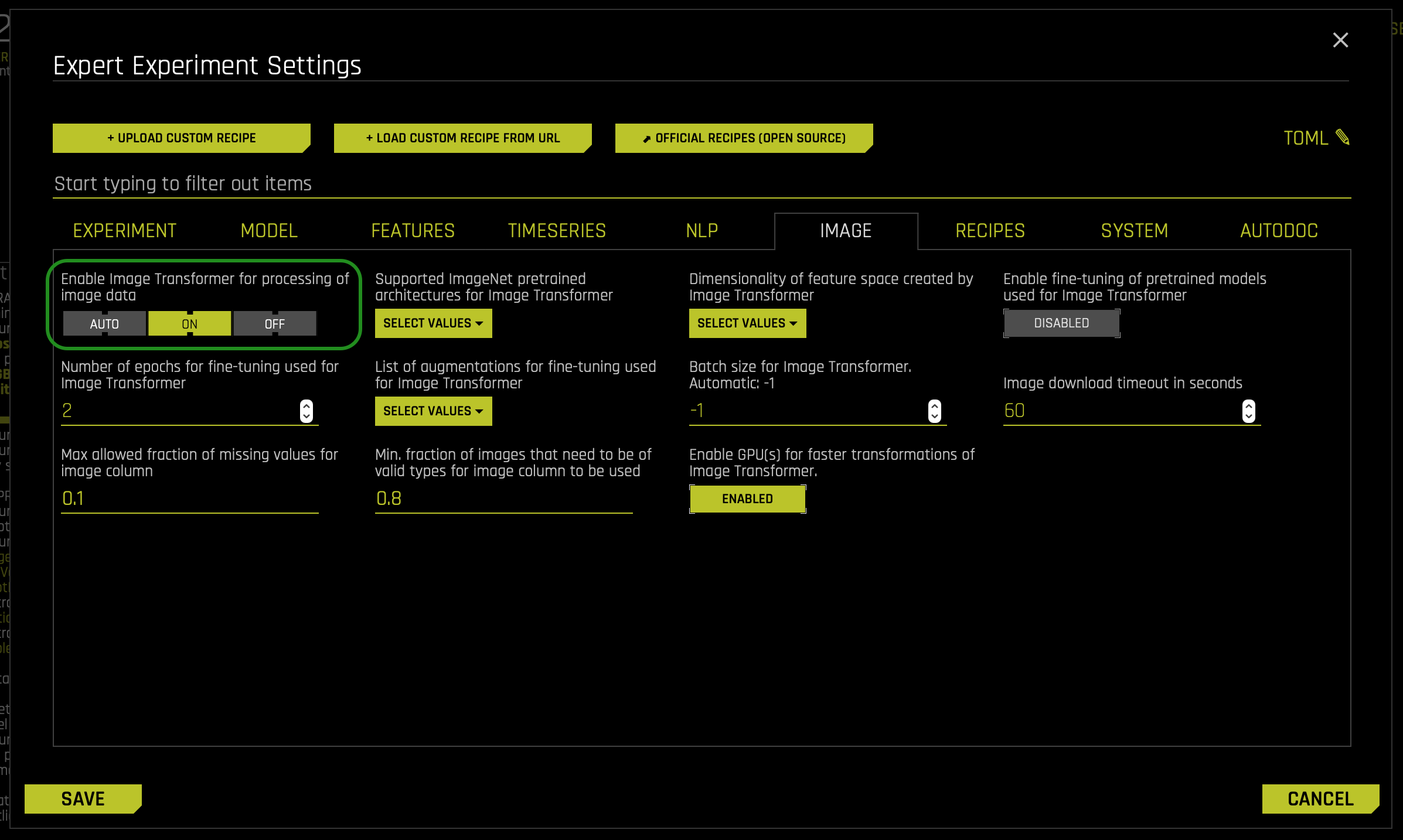
When the Image Transformer is enabled, Driverless AI defaults the xception ImageNet Pretrained Architecture for the Image Transformer. As mentioned in task 2, Driverless AI offers an array of supported ImageNet pre-trained architectures for image transformer. You can find it in the Expert Settings under the Image Tab under the following settings: Supported ImageNet pre-trained Architecture for Image Transformer (as observed in the image below):
The CNN Xception ImageNet Architecture is an extension of the Inception Architecture, where the Inception modules have been replaced with depthwise separable convolutions. As an overview, Xception takes the Inception hypothesis to an eXtreme where 1×1 convolutions capture cross-channel (or cross-feature map) correlations. Right after, spatial correlations within each channel are captured via the regular 3×3 or 5×5 convolutions. Thus, this approach is identical to replacing the Inception module with depthwise separable convolutions. To note, Xception slightly outperforms Inception v3 on the ImageNet dataset and outperforms it on a larger image classification dataset with 17,000 classes. With the above in mind, that is why we say that Xception is an extension of the Inception architecture, which replaces the standard Inception modules with depthwise separable convolutions. To learn more about other architecures please refer to the following article: Illustrated: 10 CNN Architectures.
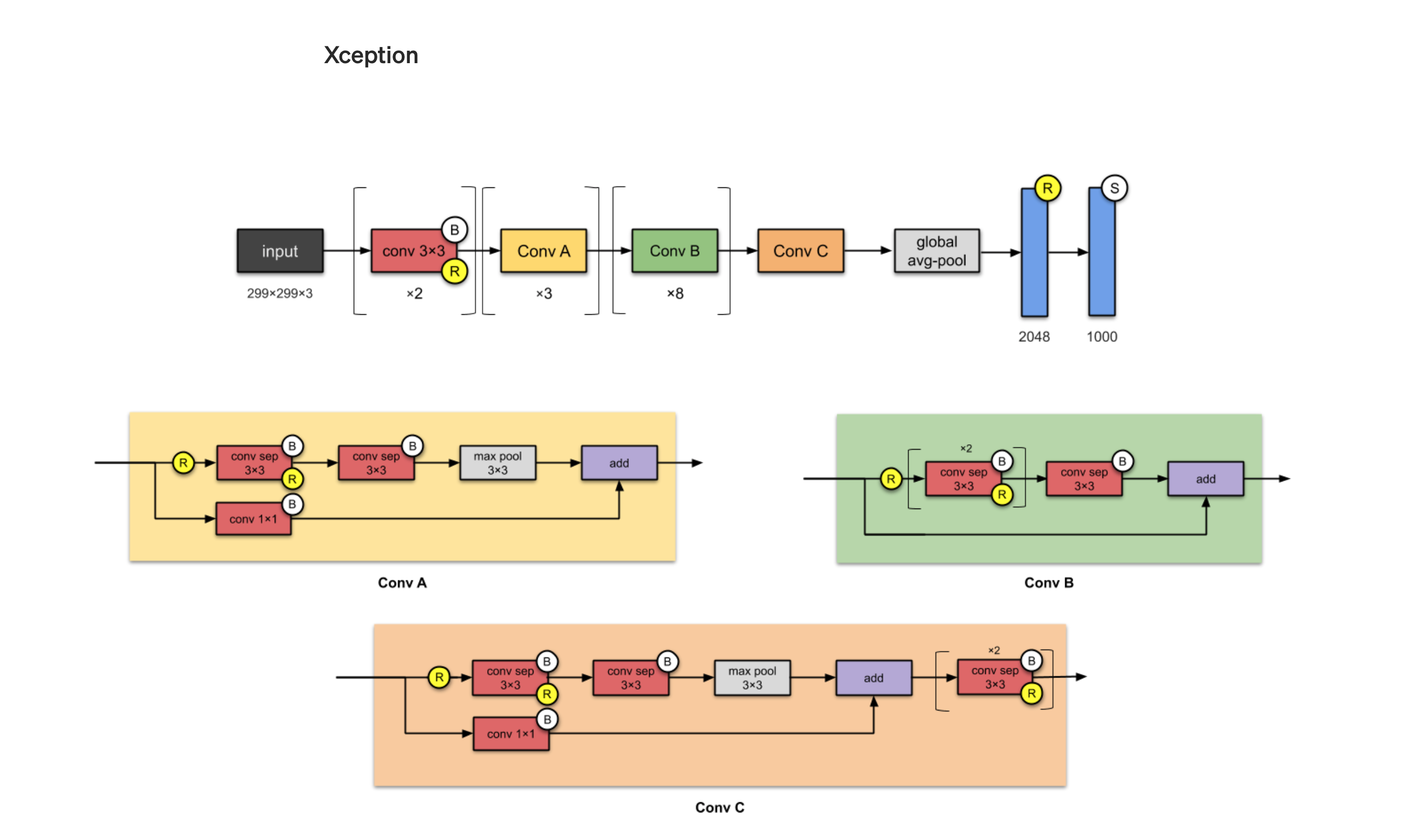
Figure 8. Xception
Note:
- Multiple transformes can be activated at the same time to allow the selection of multiple options. In this case, embeddings from the different architectures are concatenated together (in a single embedding).
In terms of which architecture to use, the answer is more complicated than one might think. There are a lot of CNN architectures out there, but how do we choose the best one for our problem? But exactly what is defined as the best architecture? Best can mean the simplest or perhaps the most efficient at producing accuracy while reducing computational complexity. Choosing a CNN architecture for your problem also depends on the problem you want to solve, and as of now is known that certain architectures are good and bad for certain problems. Also, to find the best architecture for your problem, you have to run your problem with several architectures and see which one provides the best efficiency or perhaps the best accuracy while reducing computational complexity. However, if your dataset is similar to the dataset used to train the architecture, you will discover better results.
Besides being able to select the ImageNet Pretrained architecture for the Image transformer, you can also Fine-Tune the ImageNet Pretrained Models used for the Image Transformer. This is disabled by default, and therefore, the fine-tuning technique was not used in our first experiment in Task 1. In a bit, we will explore a pre-built rerun of the first experiment with fine-tuning enable, and we will see how it impacts our results. But before, let us quickly review what fine-tuning does.
As mentioned above, we can define a neural network architecture by choosing an existing ImageNet architecture, but how can we avoid the need to train our neural network from scratch? Usually, neural networks are initialized with random weights that reach a level of value that allows the network to classify the image input after a series of epochs are executed. With the just mentioned, the question that must be asked now is what if we could initialize those weights to certain values that we know beforehand are already good to classify a certain dataset. In our case, the car deals dataset. If the weights are predefined to correct values, we will not need to wait for a good number of epochs, and therefore, the weights will have it much more manageable. And this can be achieved with fine-tuning.
Note: In Driverless AI, we counterpart transfer learning and fine-tuning. But transfer learning, in general, is the method of using pre-trained models on some new datasets. At the same time, fine-tuning is just one of the ways of applying transfer learning. Therefore, when we enabled fine-tuning, we specify a way to apply transfer learning. Accordingly, if our dataset is not similar to the ImageNet dataset or we want to improve the results of our model using ImageNet architectures, we can use fine-tuning.
When enabling fine-tuning, we are not limited to retrain only the classifier section of the CNN, but we are also able to retrain the feature extraction stage: the convolutional and pooling layers.
Note: In practice, networks are fine-tuned when trained on a large dataset like the ImageNet. In other words, with fine-tuning, we continue the training of the architecture with the large dataset we have imported. Fine-tuning will work better if the large dataset is not so different from the original dataset (ImageNet) our architecture was trained. (In practice, fine-tuning works for any dataset, no matter how large it differs from the ImageNet. And the reason for that is that pre-trained models in the early layers learned some simple representations like edges, strokes, etc. And these representations are always more useful than start training from the random weights). Once again, the pre-trained model will contain learned features relevant to our classification or regression problem.
Before we explore a rerun of the first experiment from Task 1, let us end this task by mentioning one more default setting that was enabled by default during the first experiment.
Driverless AI allows you to enable the dimensionality of the feature (embeddings) space by Image Transformer. We take the embeddings vector from the last global average pooling layer of the pre-trained model. For different models, it has different dimensionalities (usually ranging from 512 to 2k). And in Driverless AI, we suppress these representations to a lower number to suppress the transformer's number of features. The following are options that you can choose from:
- 10
- 25
- 100 (default)
- 200
- 300
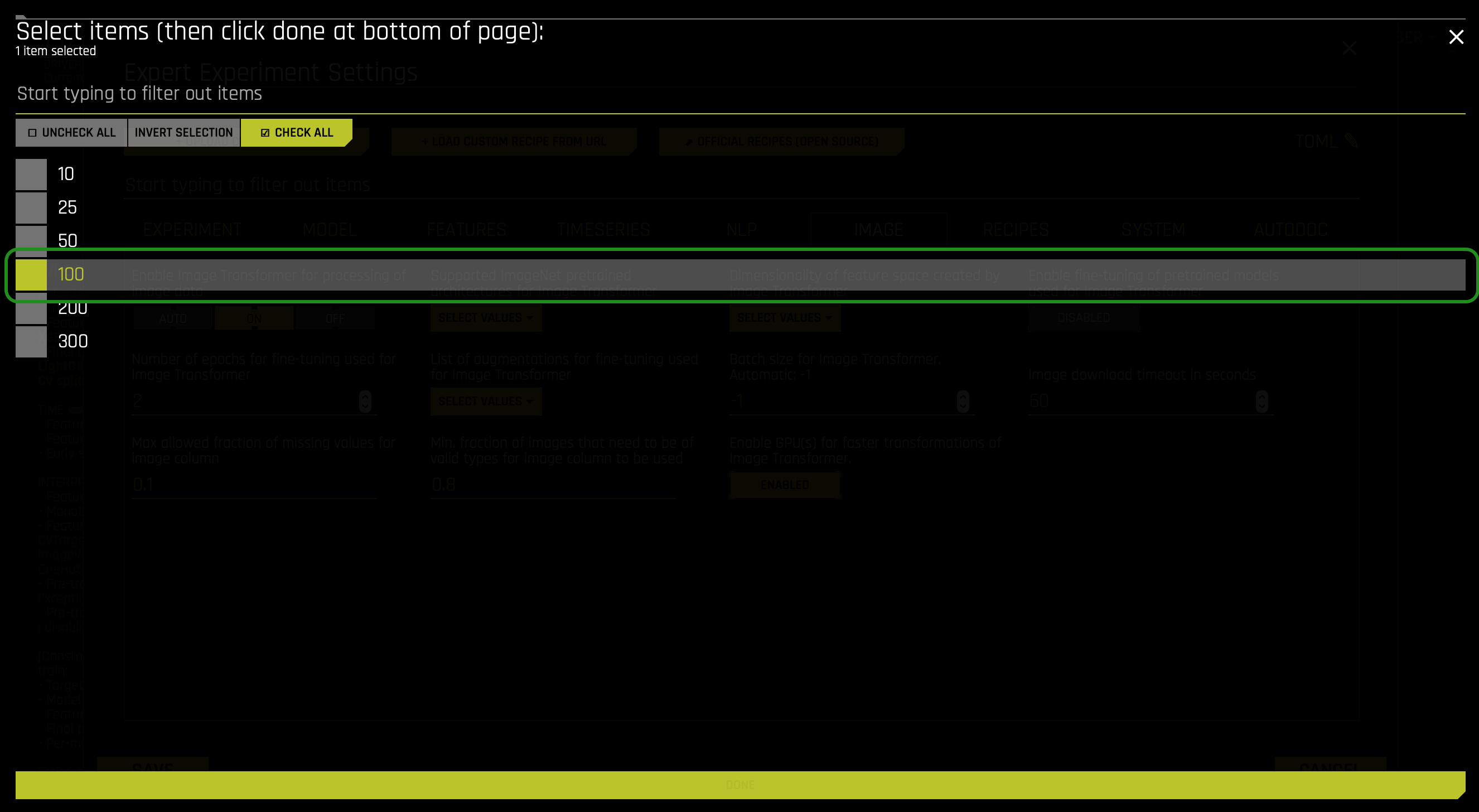
Note: You can activate multiple transformers simultaneously to allow the selection of multiple options.
Other settings exist to configure the Image Vectorizer transformer, but we will not cover all of them for this self-paced course. Though, we will discuss the other settings in future self-paced courses. For now, please refer to the Driverless AI documentation here for more details on the predefined settings used in our first experiment.
On the point of how our model performed with the auto default settings for Embeddings Transformer without Fine-tuning, you can observe the following:
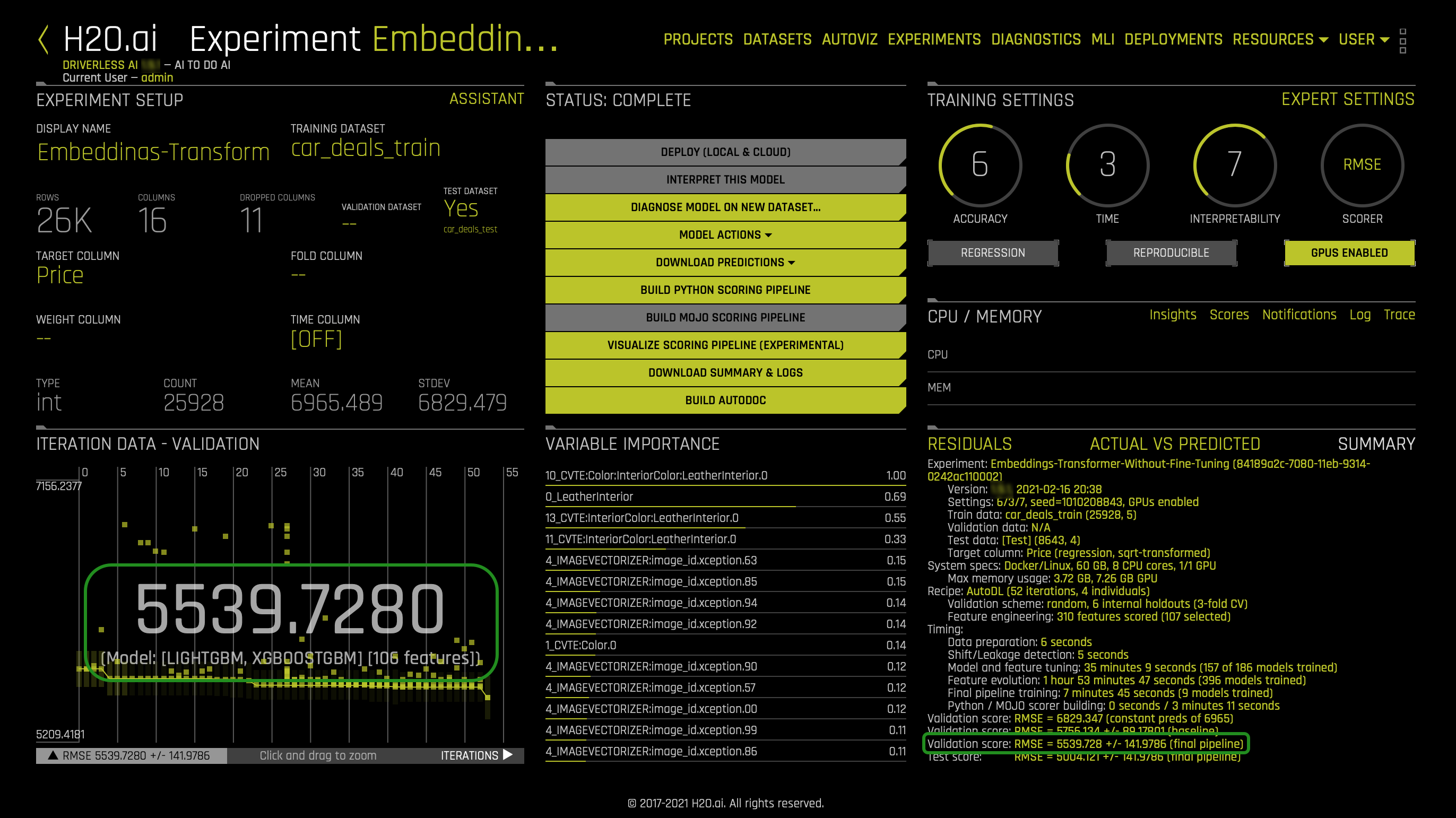
The validation score for the final pipeline model is RMSE = 5539.728 +/- 141.9786
- Note: "Root Mean Square Error (RMSE) is the standard deviation of the residuals (prediction errors).
- Residuals are a measure of how far from the regression line data points are; RMSE is a measure of how spread out these residuals are. In other words, it tells you how concentrated the data is around the line of best fit"(Ashutosh Krishna).
- Recall that RMSE is a popular formula to measure a regression model's error rate. However, one can only compare it between models whose errors are measured in the same units.
- Also, recall that RMSE has the same unit as the dependent variable in our case; our dependent variable(DV) is dollars. Consequently, what will be considered a good RMSE value depends on our DV, and, therefore, there is no absolute good or bad RMSE threshold when DV is not known.
- Because the range of our DV is from 1,000 (min) - 97,000(max) our RMSE(5539.728) will be consider small. The closer the RMSE is to zero, the better the regression model. In this case, we can say the regression model is good because the RMSE is not too far from zero. From our observations, we see that our data is pretty well concentrated around the line of best fit.
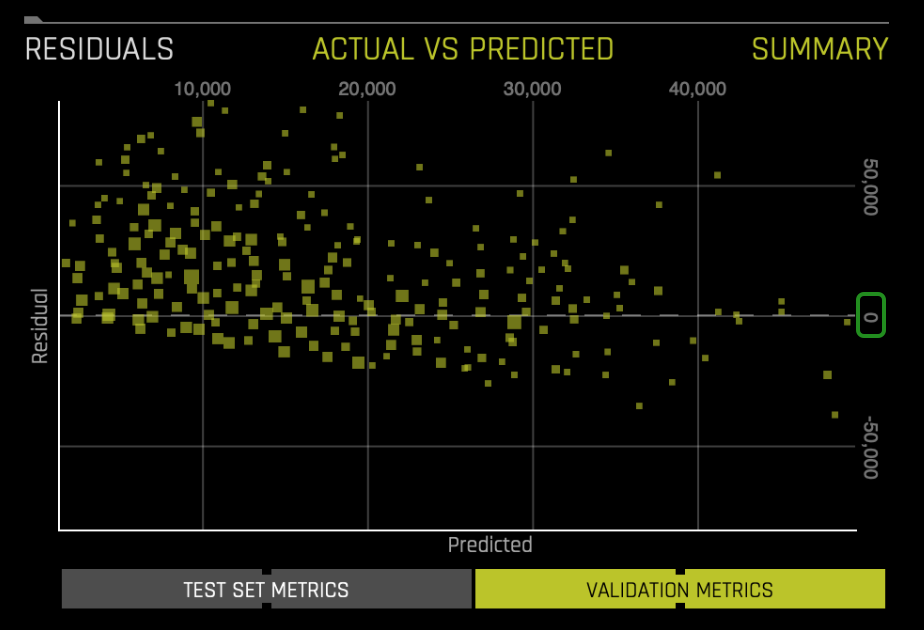
In the next section, let's explore the pre-rebuilt experiment from task one, and let's see the impact fine-tuning has on the model's performance.
References
- Krishna, Ashutosh. "Machine Learning Algorithms-Linear Regression." Data Driven investor, 14 March. 2019, medium.com/datadriveninvestor/machine-learning-algorithms-linear-regression-f89ab64ac490.
Deeper Dive and Resources
The experiment from task one has been rerun already with fine-tuning enabled. The experiment has been named Embeddings-Transformer-With-Fine-Tuning.
To showcase how fine-tuning was enabled for the first approach to image processing in Driverless AI, observe the steps that were taken and that you can take to rerun the experiment with fine-tuning:
In the Experiments section:
- Click the three vertical dots (located on the right side of the experiment) of the following experiment:
Embeddings-Transformer-Without-Fine-Tuning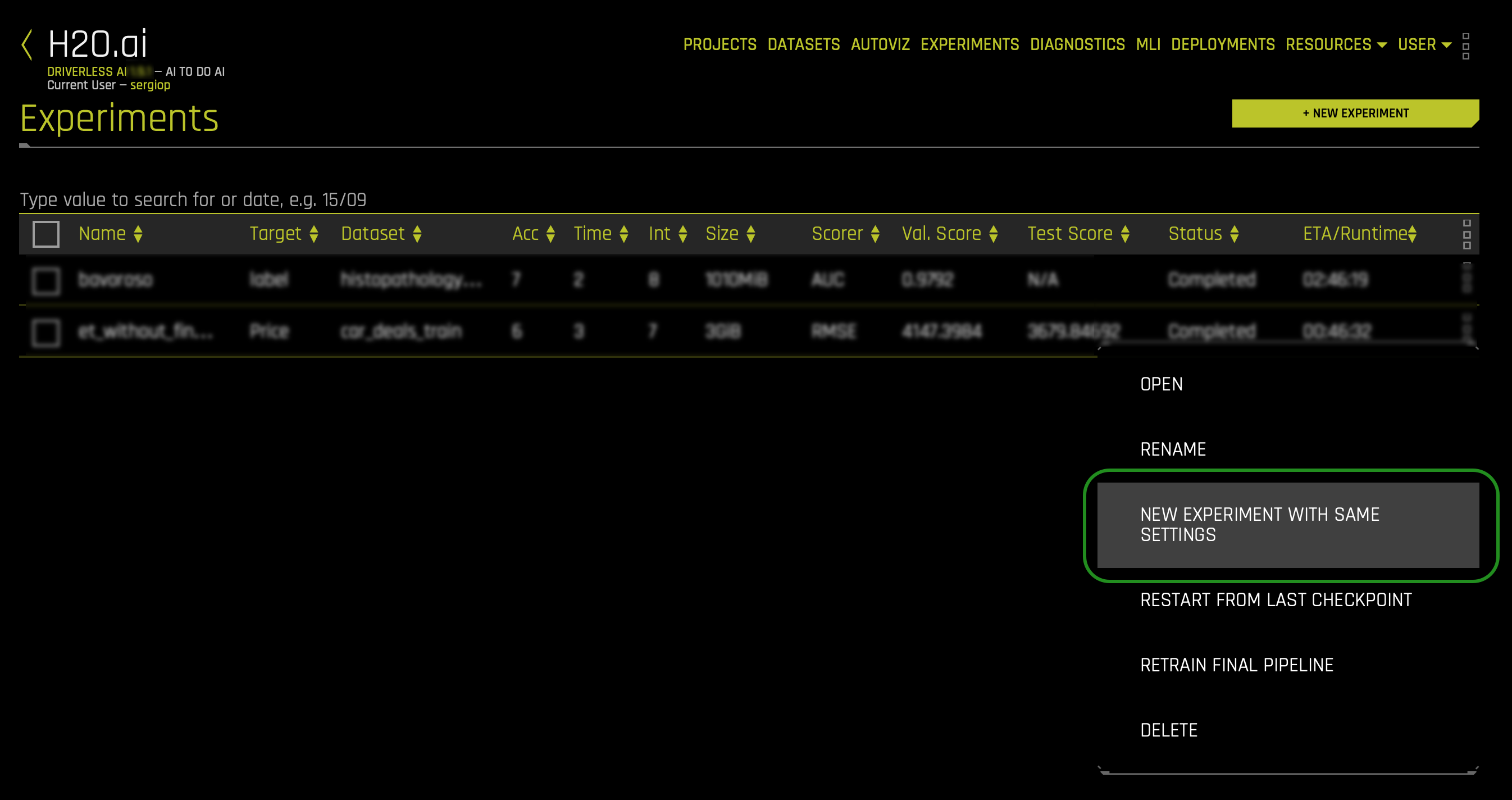
- Click the following option: NEW EXPERIMENT WITH SAME SETTINGS
- Rename the experiment to
Embeddings-Transformer-With-Fine-Tuning - Under the IMAGE tab located in the EXPERT SETTINGS click the DISABLED button under the following setting: Enable Fine-tuning of pre-trained models used for image Transformer
- This setting will change from DISABLED to ENABLED:
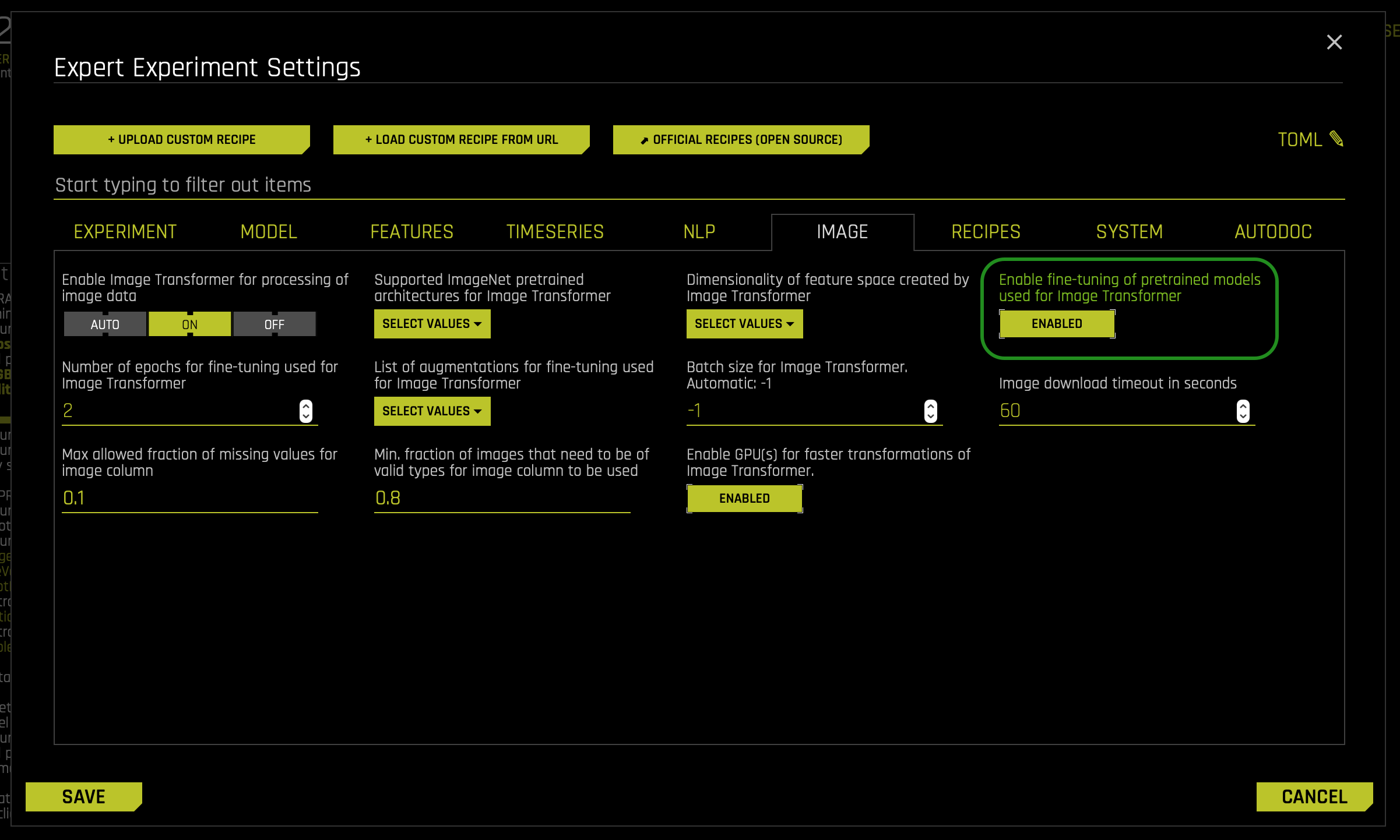
- This setting will change from DISABLED to ENABLED:
- LAUNCH EXPERIMENT:
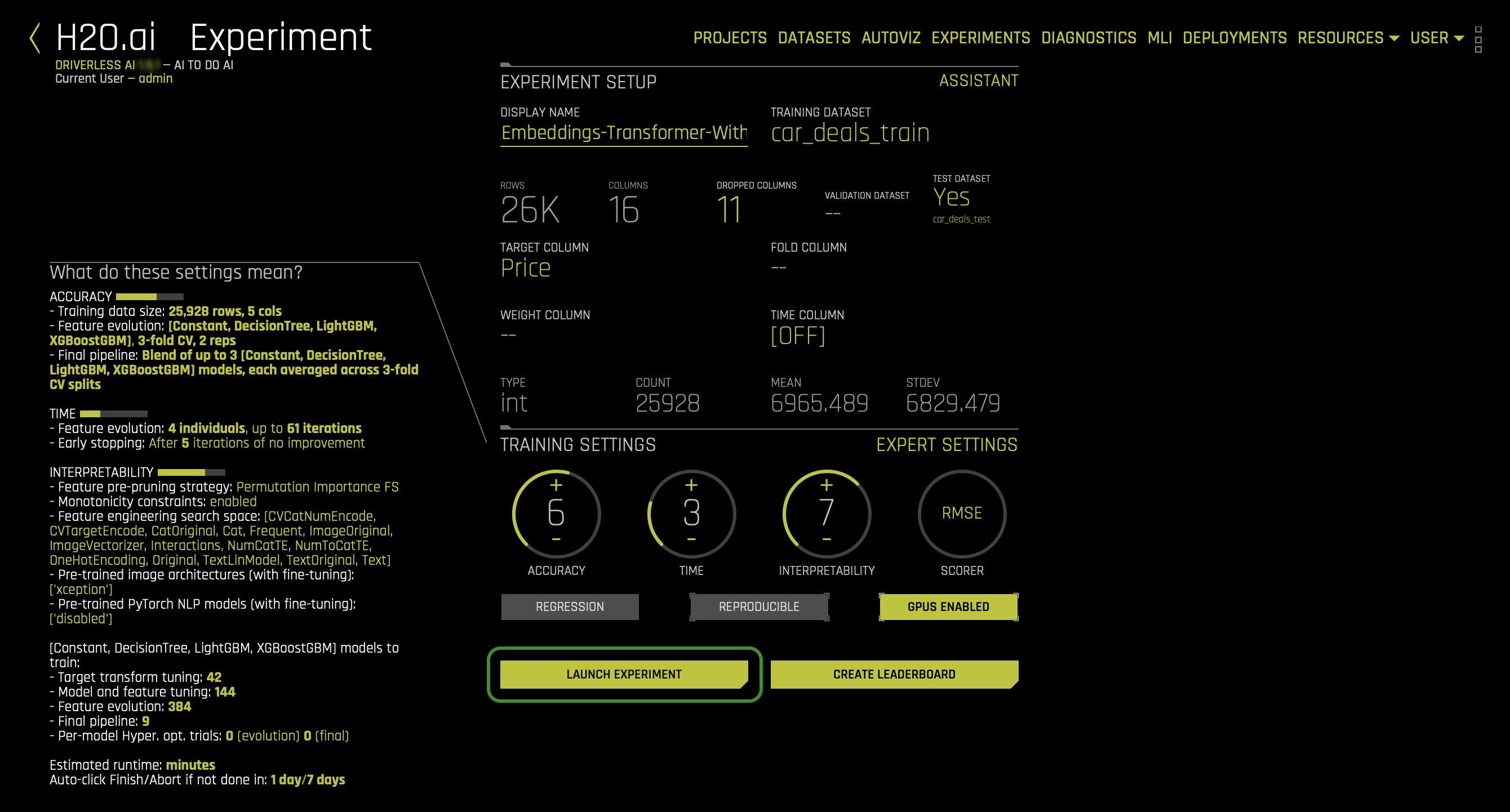
When fine-tuning is enable, Driverless AI provides a list of possible image augmentations to apply while fine-tuning the ImageNet pre-trained models used for the Image Transformer. By default, HorizontalFlip is enabled, and for purposes of this self-paced course, it was not changed. This default setting can be found and change in the IMAGE tab inside the EXPERT SETTINGS. Please refer to the Driverless AI documentation right here for a full list of all other augmentations.
NOTE: Augmentations for fine-tuning used for the Image Transformer is only available when Fine-tuning is enabled.
As well, when fine-tuning is enabled, you can specify the number of epochs for fine-tuning ImageNet pre-trained models used for the Image Transformer. This value defaults to 2. This default setting can be found and change in the IMAGE tab inside the EXPERT SETTINGS.
Now that you know how to rerun the experiment with fine-tuning let's explore the new experiment (Embeddings-Transformer-With-Fine-Tuning).
To access the experiment summary page, consider the following steps:
- Click the EXPERIMENTS option (located on the top right middle part of the screen)
- Select the following experiment: Embeddings-Transformer-With-Fine-Tuning
The following should appear:
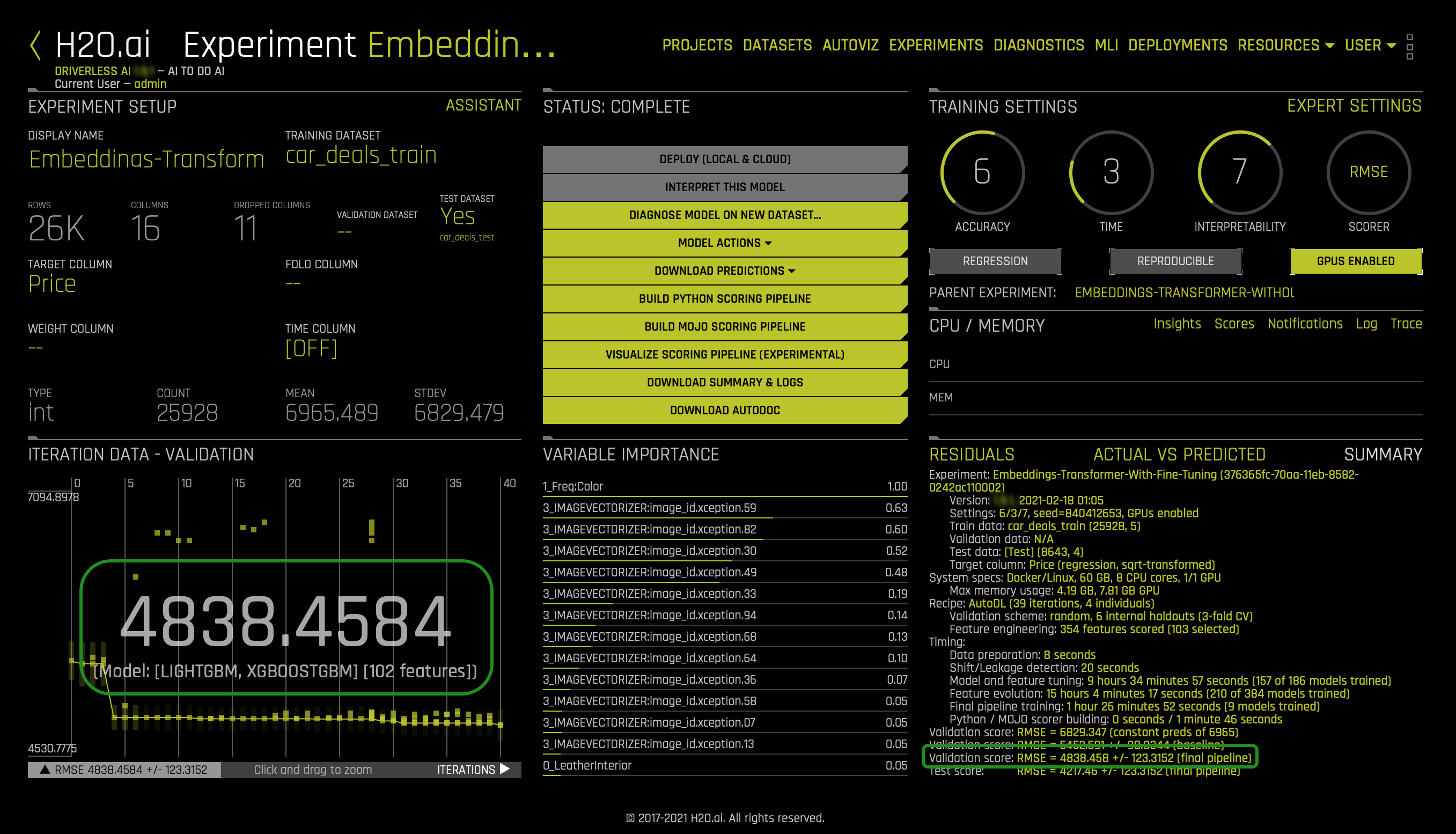
For our second experiment, we see that the validation score for the final pipeline is RMSE = 4838.458 +/- 123.3152. Recall that the RMSE for the first experiment was 5539.728 +/- 141.9786. Enabling fine-tuning improve the RMSE. The RMSE decrease by ~701.27.
For the most part, fine-tuning will lead to better results, though there are times when that will not be the case. Performance depends on the type of problem you have: If:
- Our dataset(car_deals_train) is smaller and similar to the original one(ImageNet) - you need to be careful with fine-tuning because it could be the case that other learning models can achieve better results(e.g., linear classifier).
- When the new dataset is larger and similar to the original, having more data will not over-fit the model. Therefore, we can say with confidence that fine-tuning can achieve better results.
In our case, the Xception model has been trained on ~1.2 million training images with another 50,000 images for validation and 100,000 images for testing. Although the RMSE improve, note that it didn't improve drastically. Fine-tuning could not help much, as the ImageNet has already been trained on various car models.
So how else can we improve the RMSE for the first experiment? Well, if you recall task 2, the following is stated:
- Quadrant 2. "Large dataset and similar to the pre-trained model's dataset. Here you're in la-la land. Any option works. Probably, the most efficient option is Strategy 2. Since we have a large dataset, overfitting shouldn't be an issue, so we can learn as much as we want. However, since the datasets are similar, we can save ourselves from a huge training effort by leveraging previous knowledge. Therefore, it should be enough to train the classifier and the top layers of the convolutional base"(Pedro Marcelino).
Note that in Driverless AI and when we enabled fine-tuning, we unfreeze the whole network.
Now in the next task, let's explore automatic image model as the second approach to image processing in Driverless AI.
References
- Marcelino, Pedro. "Transfer Learning from Pre-Trained Models." Medium, Towards Data Science, 23 Oct. 2018, towardsdatascience.com/transfer-learning-from-pre-trained-models-f2393f124751.
Deeper Dive and Resources
Automatic Image Model is the second approach to modeling images in Driverless AI. Automatic Image Model is an AutoML model that accepts only an image and a label as input features. This Model automatically selects hyperparameters such as learning rate, optimizer, batch size, and image input size. It also automates the training process by selecting the number of epochs, cropping strategy, augmentations, and learning rate scheduler.
Automatic Image Model uses pre-trained ImageNet models and starts the training process from them. The possible architectures list includes all the well-known models: (SE)-ResNe(X)ts; DenseNets; EfficientNets; Inceptions; etc.
Unique insights that provide information and sample images for the current best individual model are available for the Automatic Image Model. These insights are available while an experiment is running or after an experiment is complete. In a moment, we will see how we can use these insights to analyze an experiment predicting true cases of metastatic cancer.
Notes:
- This modeling approach only supports a single image column as an input
- This modeling approach does not support any transformers
- This modeling approach supports classification and regression experiments
- This modeling approach does not support the use of mixed data types because of its limitation on input features
- This modeling approach does not use Genetic Algorithm (GA)
- The use of one or more GPUs is strongly recommended for this modeling approach
To illustrate how we will use the second approach, let's explore the pre-built experiment predicting true cases of metastatic cancer. Before that, let's see how you can run the experiment while learning how to active AutoML when modeling images in Driverless AI.
In the Datasets page:
- Import the dataset by selecting the AMAZON S3 option
- Paste the following in the search bar:
s3://h2o-public-test-data/bigdata/server/ImageData/histopathology_train.zip - Selet the followign option: histopathology_train.zip [488.5MB]
- CLICK TO IMPORT SELECTION
- The following dataset should appear on the Datasets page: histopathology_train.zip
- Click on the histopathology_train.zip and click the PREDICT option
- Name your experiment as follows:
Metastatic Cancer - Automatic Image Model - Select label as the Target Column
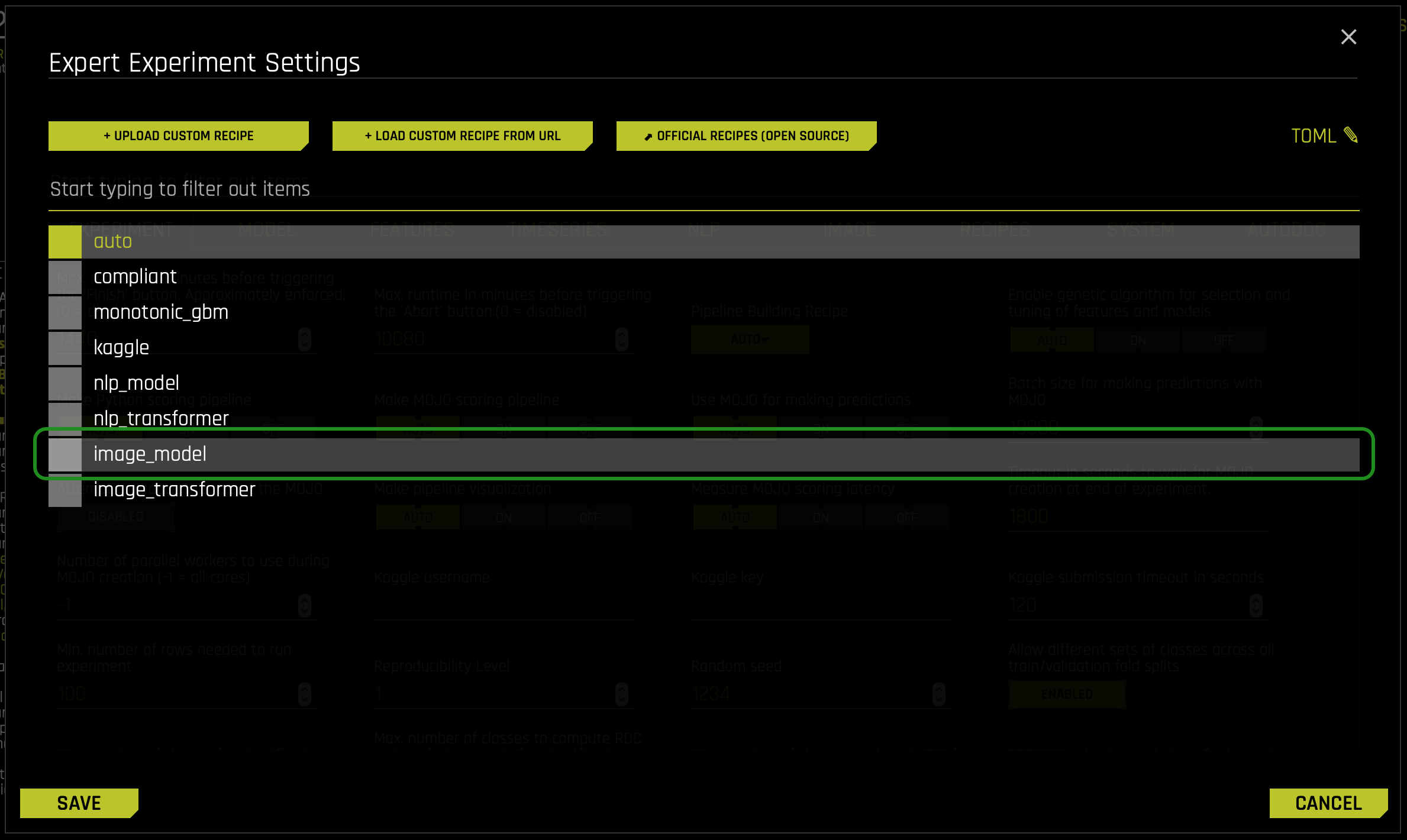
- To enable the Automatic Image Model, navigate to the Pipeline Building Recipe expert setting and select the image_model option
- You can find the Pipeline Building Recipe inside the EXPERIMENT tab inside the EXPERT SETTINGS:
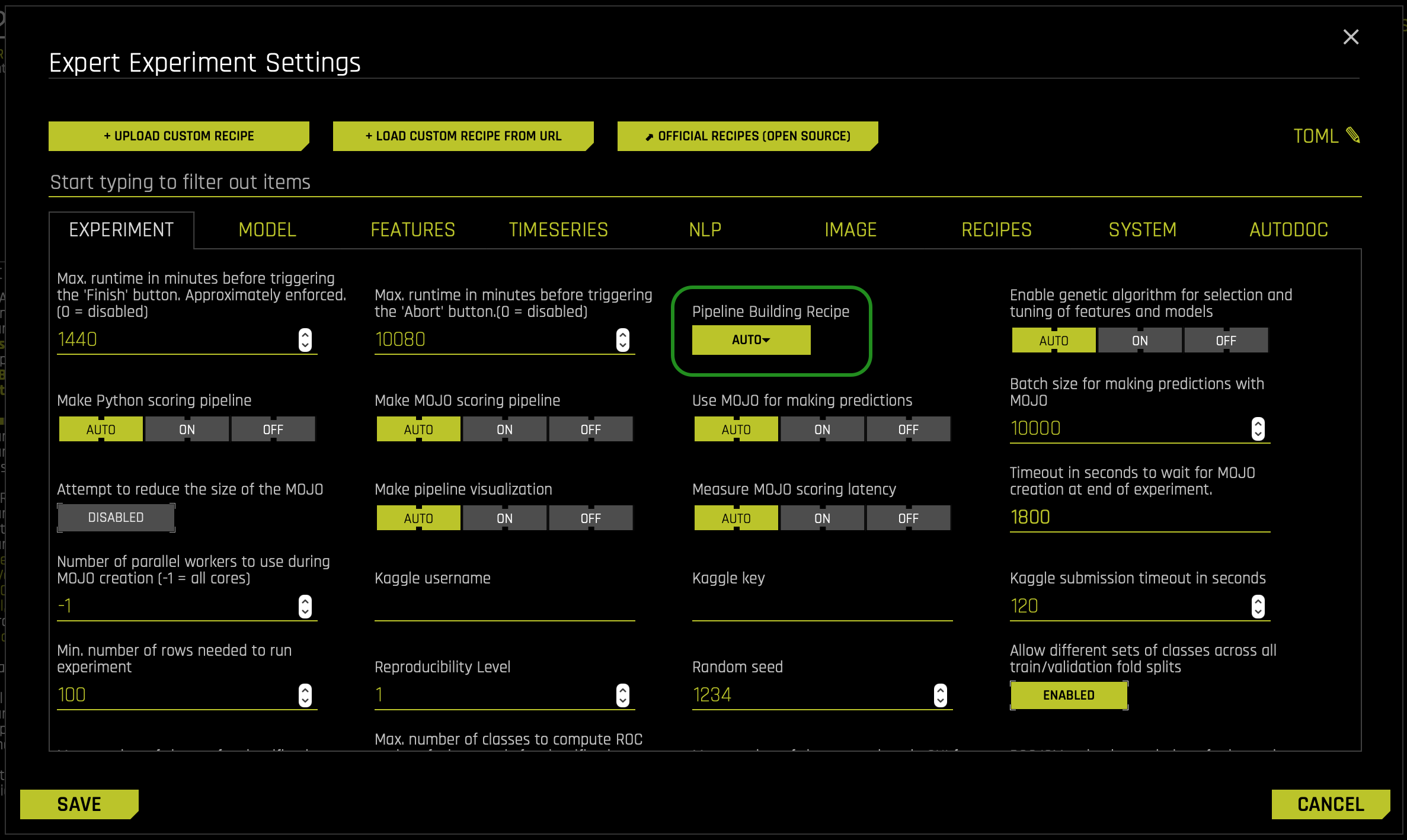
 Right after, a warning dialog box will appear stating the following about selecting image_model:
Right after, a warning dialog box will appear stating the following about selecting image_model:
- You can find the Pipeline Building Recipe inside the EXPERIMENT tab inside the EXPERT SETTINGS:
- In terms of the training settings, don't change them; we will use the recommended settings.
- LAUNCH EXPERIMENT:
Now that you know how to run the experiment using the AutoML model, let's explore the results and use insights to see images and information about the current best individual model for the Automatic Image Model. As mentioned, this experiment has been pre-built and can be found in the Experiment section.
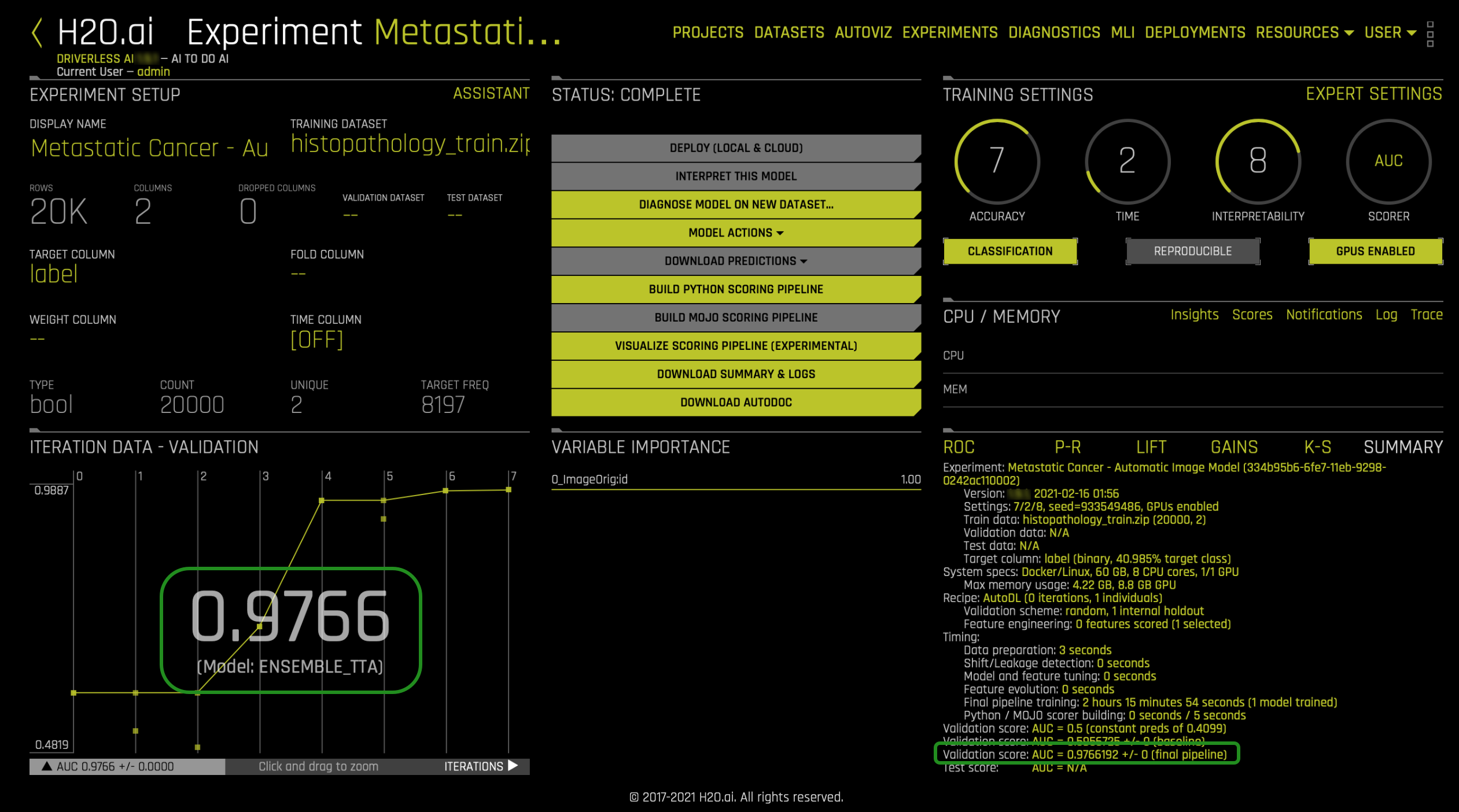
- In the Experiment section, select the following experiment: Metastatic Cancer - Automatic Image Model. The following will appear:
As mentioned above, this second modeling approach only supports a single image column as an input. Therefore, let's see the dataset used for the Metastatic cancer experiment.
- In the Datasets page, click the following dataset: histopathology_train.zip
- Select the DETAILS option
- On the top right corner of the page, click DATASET ROWS
- The following will appear:
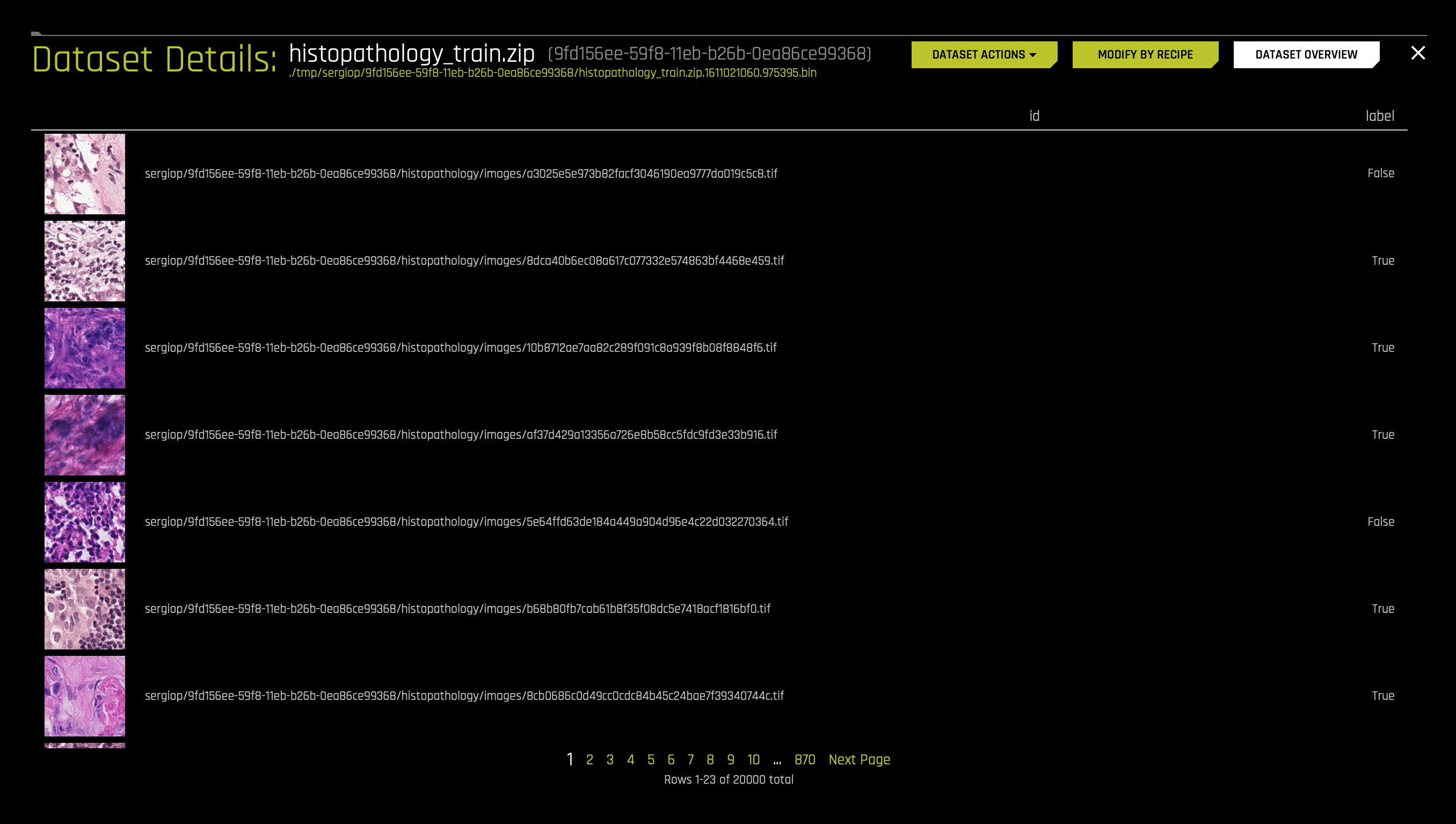
As we can see, the images (id) have labels of bool storage type. In this case, True refers to a true case of metastatic cancer, and False refers to a false case of metastatic cancer.
To further see the difference between the first and second approach to Image processing, let's see how the automated selected settings generated a model to classify metastatic cancer cases (True or False).
On the bottom right corner of the complete experiment screen select the ROC graph; the following should appear:
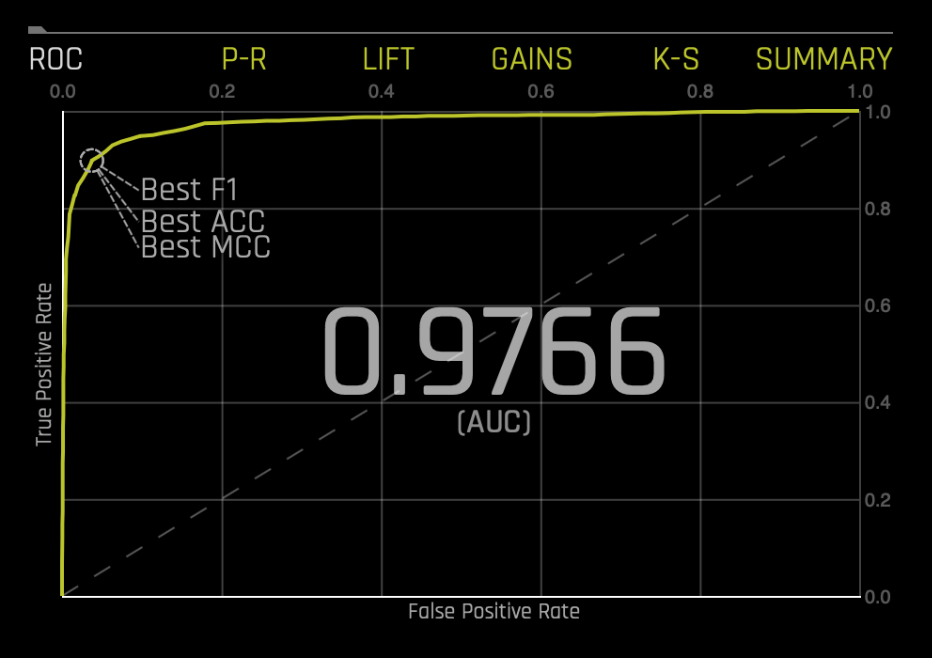
Before we determine whether the AUC (Area under the ROC Curve) is good or bad, consider the following:
- An AUC value of 0.9 - 1.0 will be considered Excellent
- An AUC value of 0.8 - 0.9 will be considered Very Good
- An AUC value of 0.7 - 0.8 will be considered Good
- An AUC value of 0.6 - 0.7 will be considered Satisfactory
- An AUC value of 0.5 - 0.6 will be considered Unsatisfactory
With the above in mind, our AUC of 0.9766 will mean that our model is Excellent. Note that this model was not tested with a test dataset, and therefore, it could be the case that our AUC can decrease, but for now, it's safe to say that our model is doing a great job at classifying metastatic cancer cases (True or False). Also note, that the difference between the metastatic dataset and the ImageNet dataset didn't prevent good results for this model.
For this model, the confusion matrix looks as follows:
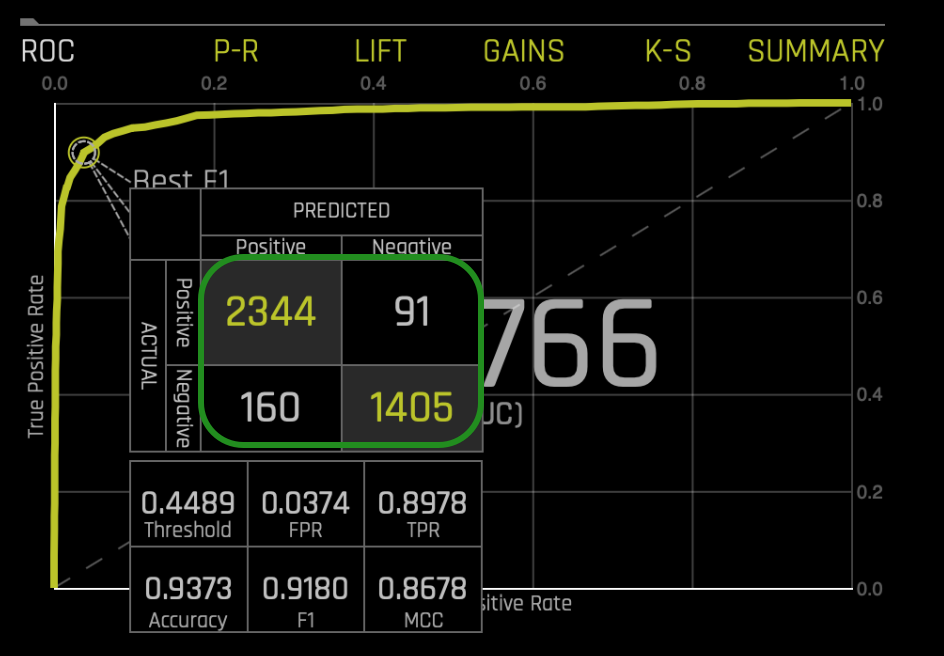

For the most part, having low False Negatives and False Positives will be considered reasonable. With that in mind, this model will be acceptable. For example, when calculating accuracy we see 0.9373((Acc = (TN + TP) / (TN + FP + FN + TP))), a high value.
Now let's look at the Insights of the current best individual model for the Automatic Image Model. On the top right corner of the complete experiment screen click Insights (training settings area).
The Insights page contains the following about the current best individual model:
- Best individual hyperparameters:
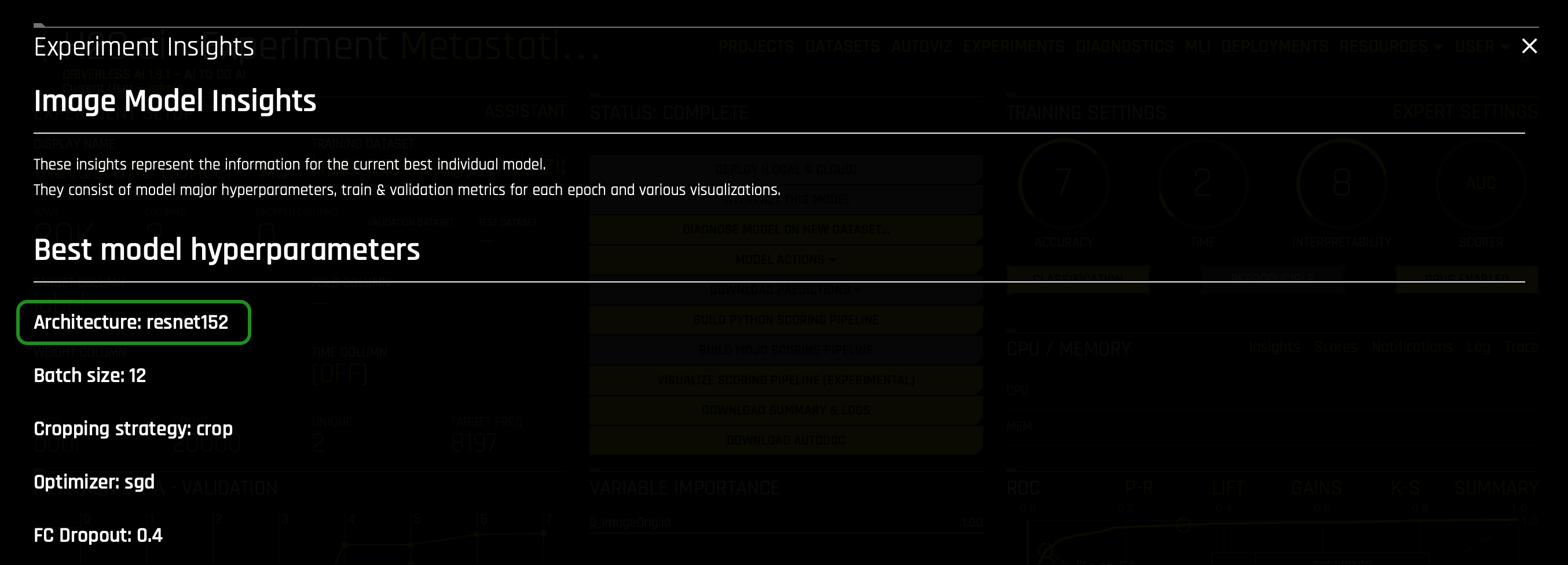
- Note: The resnet152 architecture (a residual CNN for Image Classification Tasks) is 152 layers deep. This pretrained model has been trained on more than a million images from the ImageNet database.
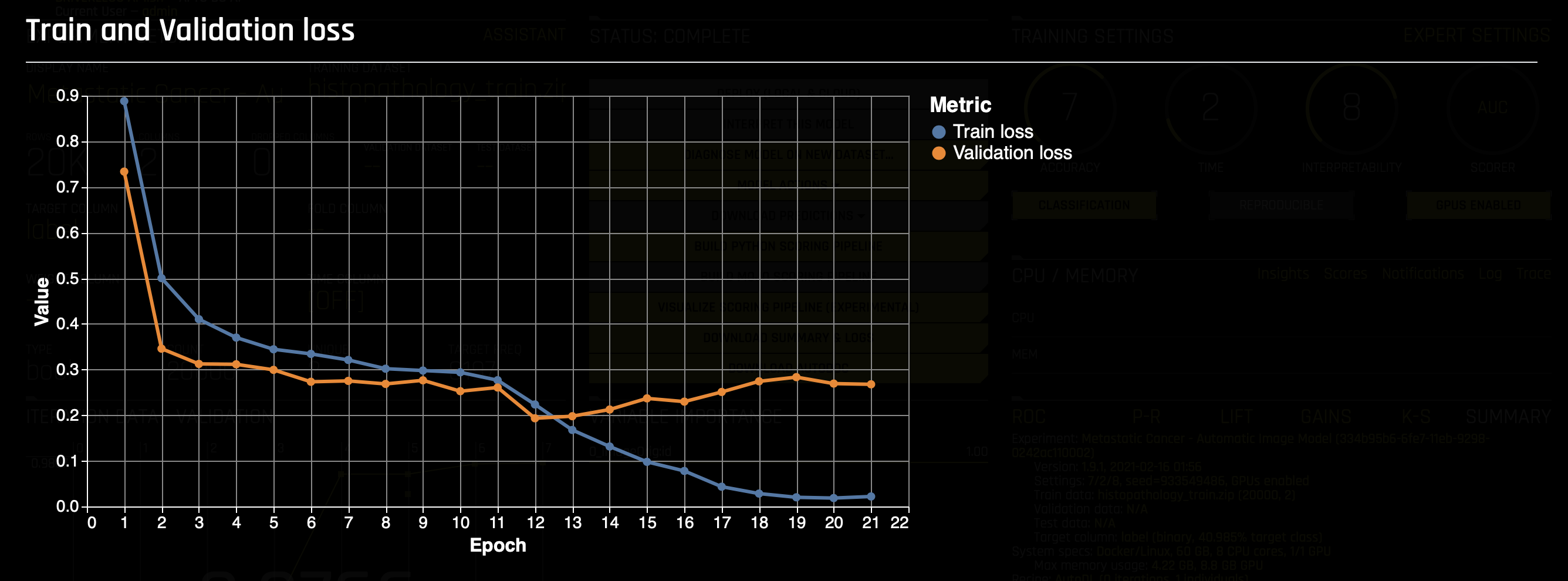
- Train and validation loss graph(by epoch):
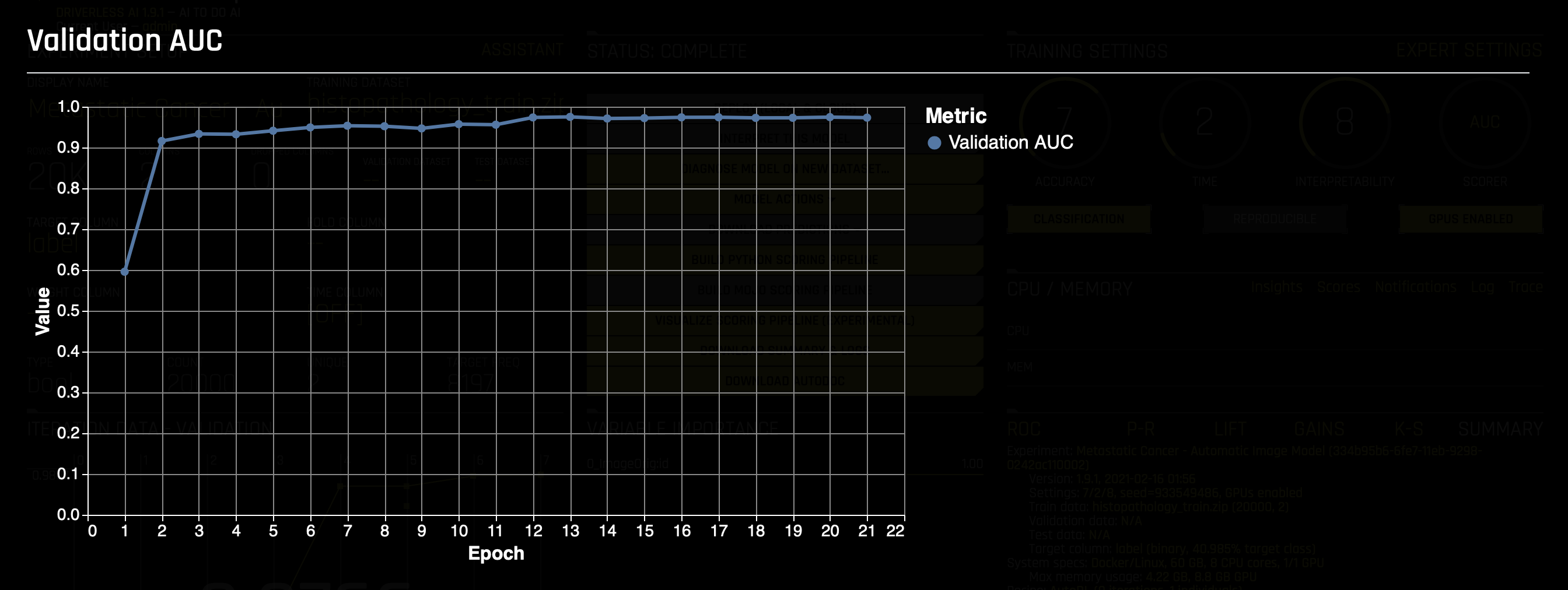
- Validation Scorer graph (by epoch):
- Sample train and augmented train images:
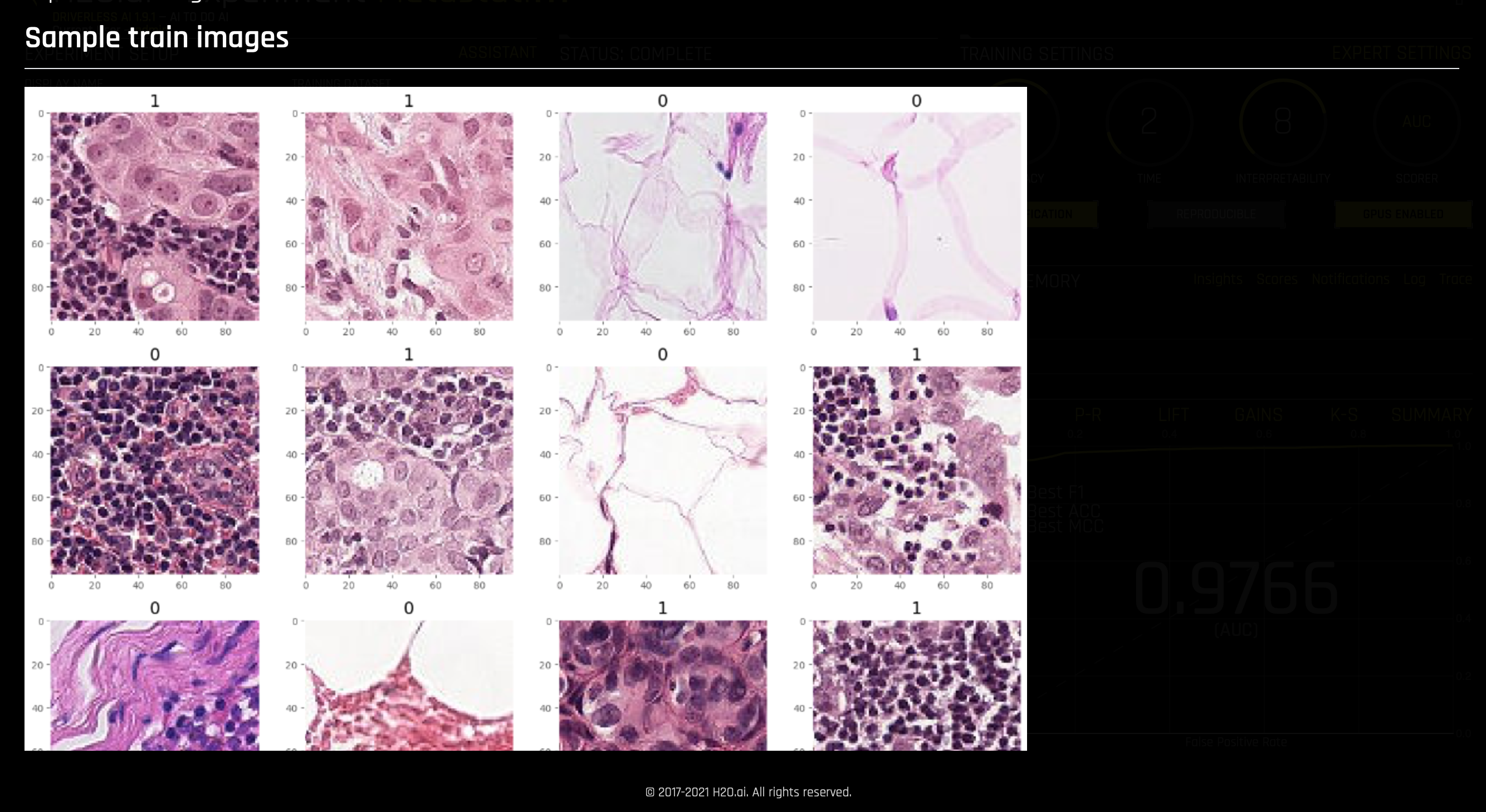
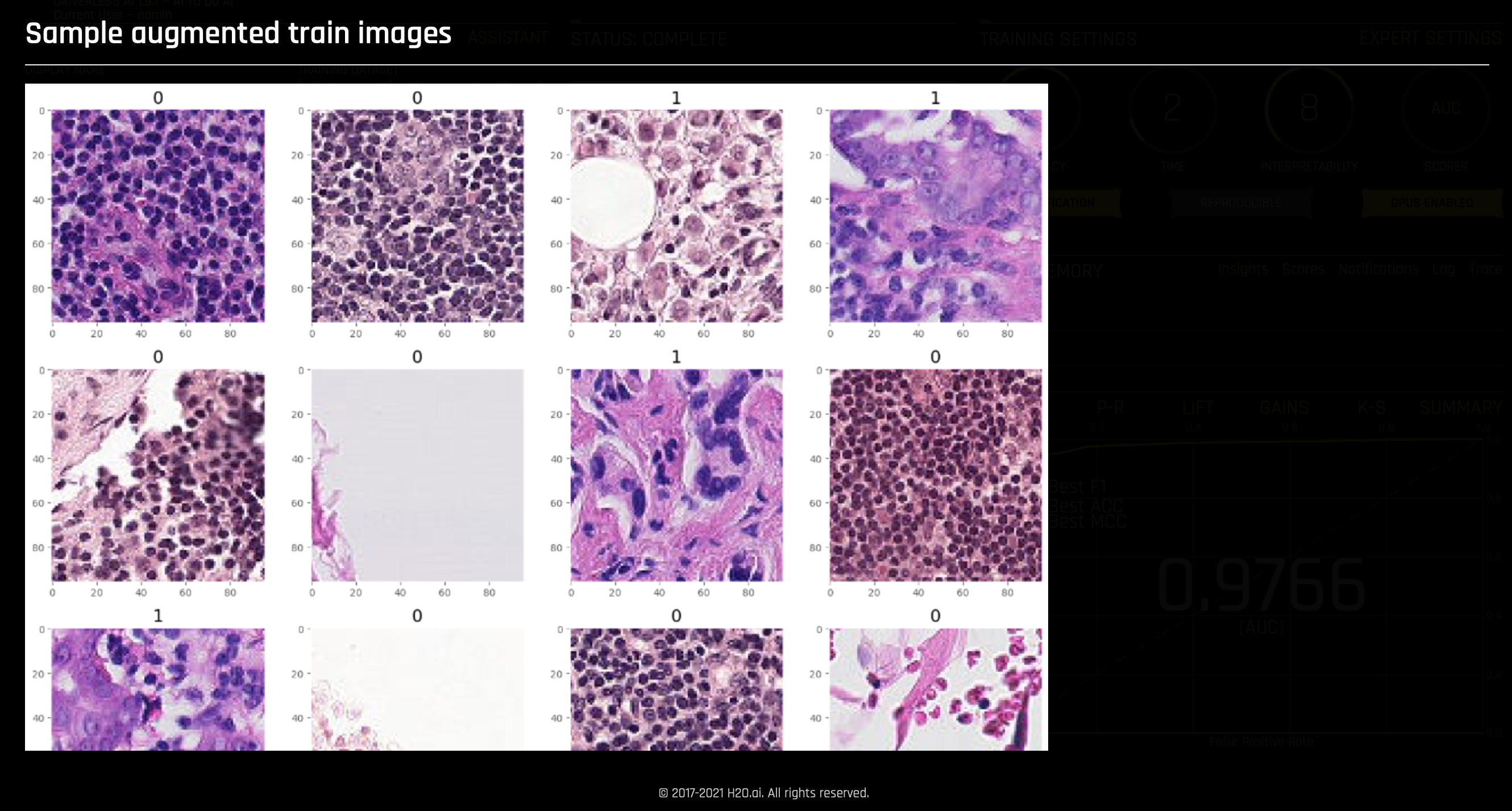
- Note: Zero (0) refers to False and One (1) refers to True
- Note: Image augmentation is a technique that can artificially expand the size of a training dataset by creating modified versions of images in the dataset. To make new images, you can change original images. For example, you can make a new image a little darker; you could cut a piece from the original image, etc. Therefore, you could create an infinite amount of new training samples. For example:
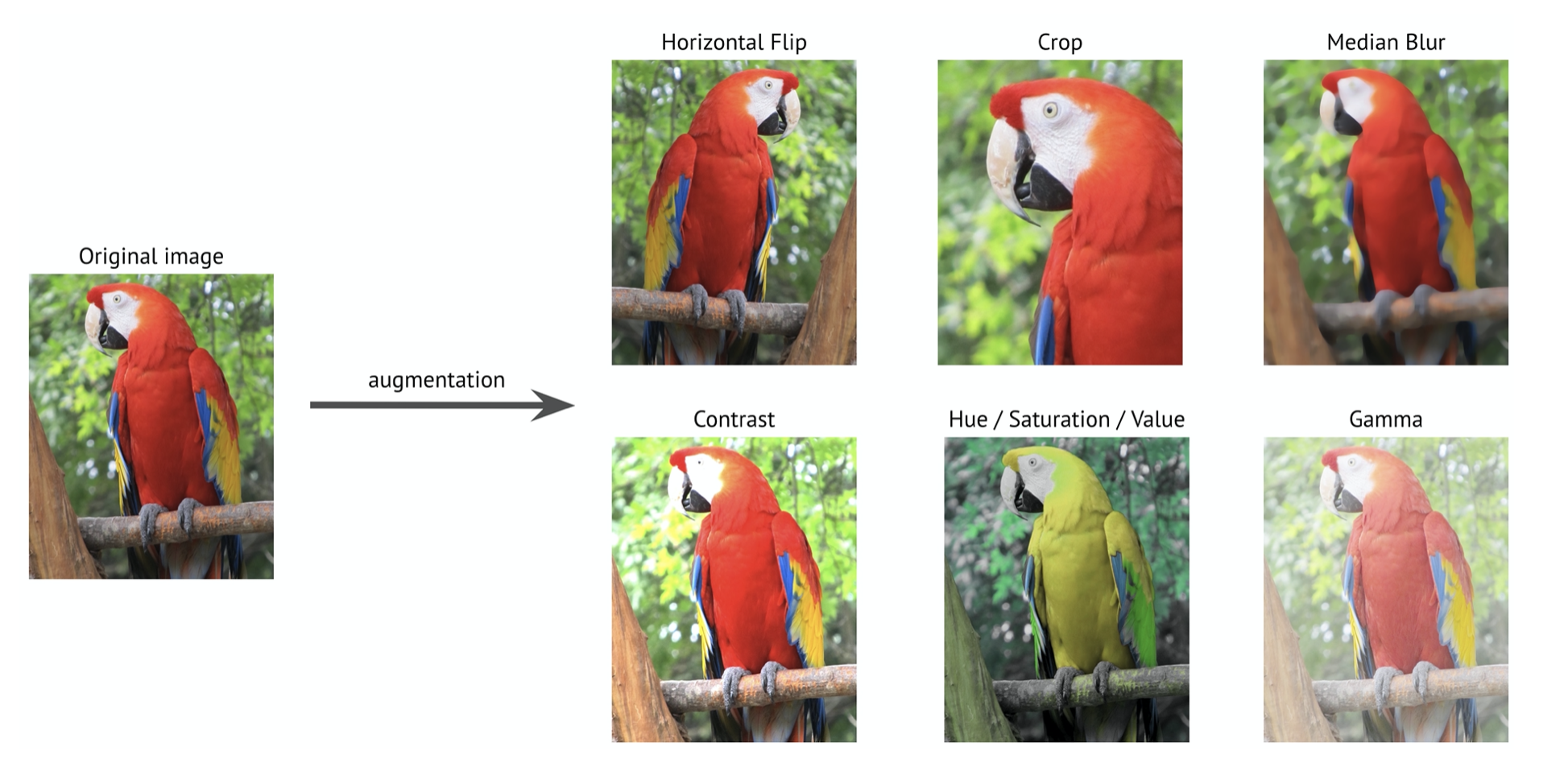
Figure 9. Augmentation
- Sample validation error images:
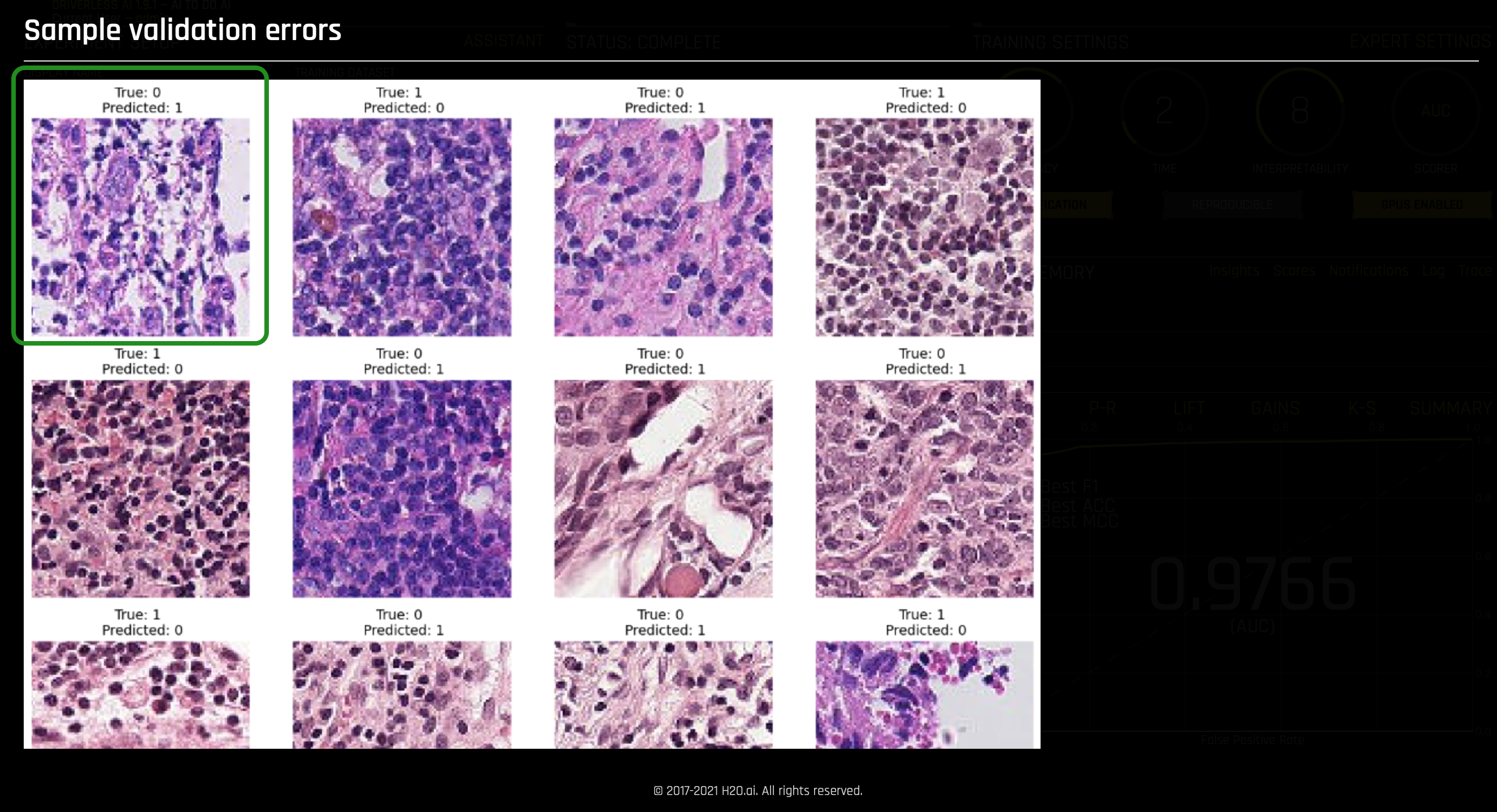
- The above sample validation errors display instances when the model predicted wrongly. For example, the top left corner sample shows the model predicting a True (1) case of metastatic cancer when True is 0(False).
- Sample Grad-CAM visualization:
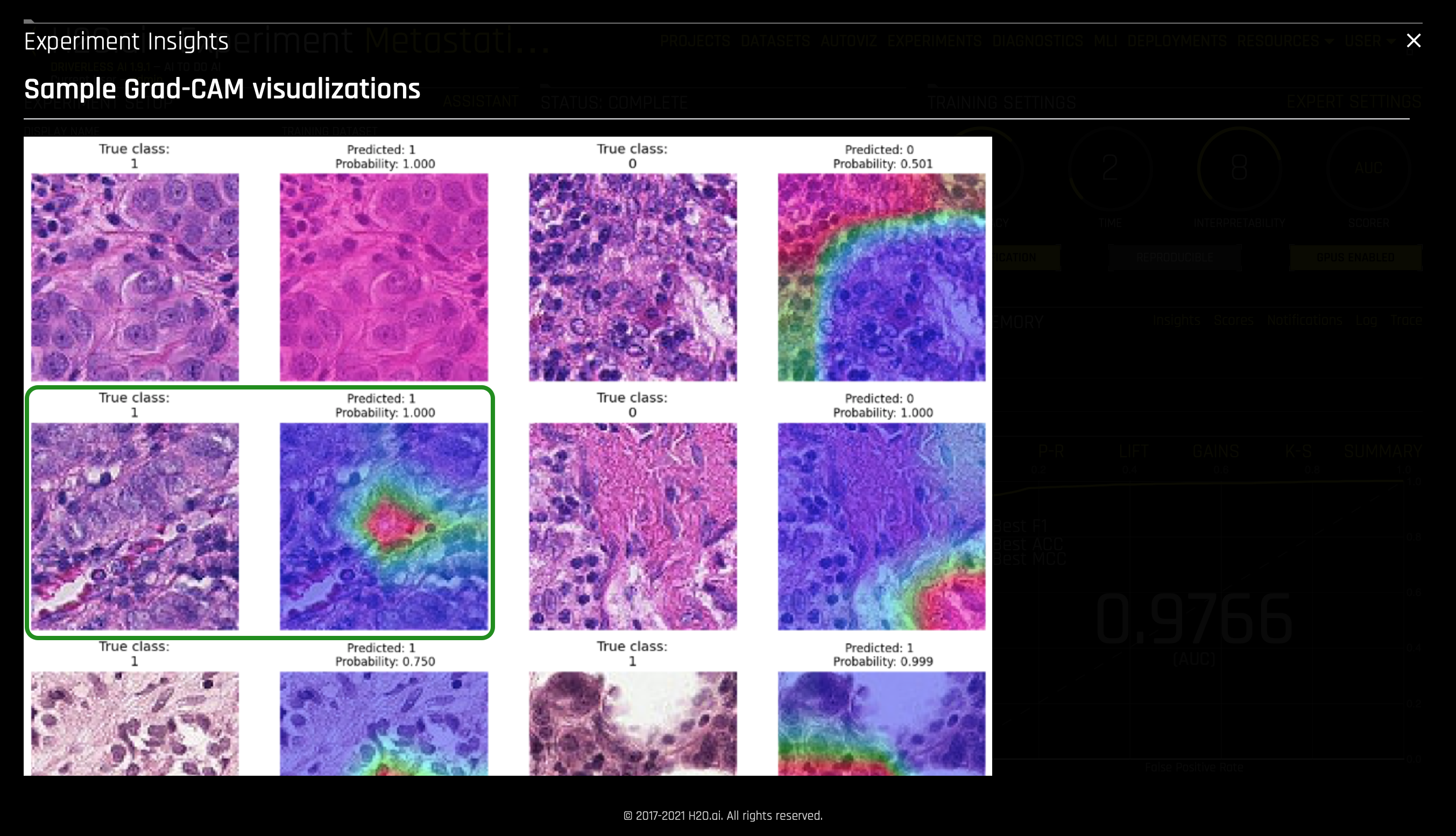
- The Grad-CAM visualization samples allow us to see where the model looked when generating a prediction and probability. In the two pair images on the middle left of the image, we see the images being label as part of the True class (1). In this sample, we see that the model observed the middle part of the image when predicting that this image belongs to the True class and that its probability is 1.000.
Note: For time series and Automatic Image Model experiments, you can view detailed insights while an experiment is running or after an experiment is complete by clicking on the Insights option.
Now in the next task, let's compare and contrast each image modeling approach, and let's discuss several scenarios when a given approach will be better. In particular, and as a point of distinction, let's discuss how, between the two approaches, only the Embeddings Transformer approach supports a MOJO Scoring Pipeline.
References
Under what circumstances a particular approach will be better? When answering this question, consider the following:
- When your classification or regression problem is making use of a mixed data type, you can only use the Embeddings Transformer (Image Vectorizer) approach:
- When deciding whether to use it with or without fine-tuning, you can consider what was discussed in Tasks 2 and 3. In general, if your dataset is not similar to the ImageNet dataset or we want to improve the results of our model using ImageNet architectures, we can use fine-tuning
- Without fine-tuning: the experiment will usually finish faster but has the lowest performance
- With fine-tuning: the experiment will be slower with fine-tuning, but should produce better results
- Automatic Image Model: the slowest by far, but produces the best results
- When deciding whether to use it with or without fine-tuning, you can consider what was discussed in Tasks 2 and 3. In general, if your dataset is not similar to the ImageNet dataset or we want to improve the results of our model using ImageNet architectures, we can use fine-tuning
- When your dataset image column is crucial to your regression or classification problem, it is best to use the second approach: Automatic Image Model. Hence, if images are not playing a crucial role in your experiment, you can use the Embeddings Transformer
- Python scoring and C++ MOJO Scoring are supported for the image transformer
- Presently, only Python scoring is supported for Automatic Image Model
With the above in mind, you are ready to generate your Image Models. Note: As of now, Driverless AI supports the following problem types:
- Classification (single-label)
- Regression
Though in the roadmap, Driverless AI will be able to support the following problem types:
- Semantic segmentation
- Object detection
- Instance segmentation
Check out the following self-paced course in the learning path: Get Started with Open Source Custom Recipes. In it, you will learn the following:
- What is Bring Your Own Recipe?
- What is a recipe?
- Types of Driverless AI open-source recipes available
- How to upload the recipes into Driverless AI as raw URL's and .py files
- Analyze models that made use of custom recipes
To understand more about the C++ MOJO Scoring, we recommend checking the following three self-paced courses in order:
Thank you to everyone that helped make this self-paced course possible:
- Yauhen Babakhin - Data Scientist | Kaggle Grandmaster
- Jo-fai (Joe) Chow - Data Science + Community + #360Selfie