Database-like ops benchmark
This page aims to benchmark various database-like tools popular in open-source data science. It runs regularly against very latest versions of these packages and automatically updates. We provide this as a service to both developers of these packages and to users. You can find out more about the project in Efficiency in data processing slides and talk made by Matt Dowle on H2OWorld 2019 NYC conference.
We also include the syntax being timed alongside the timing. This way you can immediately see whether you are doing these tasks or not, and if the timing differences matter to you or not. A 10x difference may be irrelevant if that's just 1s vs 0.1s on your data size. The intention is that you click the tab for the size of data you have.
Task
groupby
0.5 GB
basic questions

advanced questions

5 GB
basic questions

advanced questions

50 GB
basic questions

advanced questions

join
0.5 GB
basic questions

5 GB
basic questions

50 GB
basic questions

groupby2014
0.5 GB
basic questions

5 GB
basic questions

50 GB
basic questions

Details
groupby
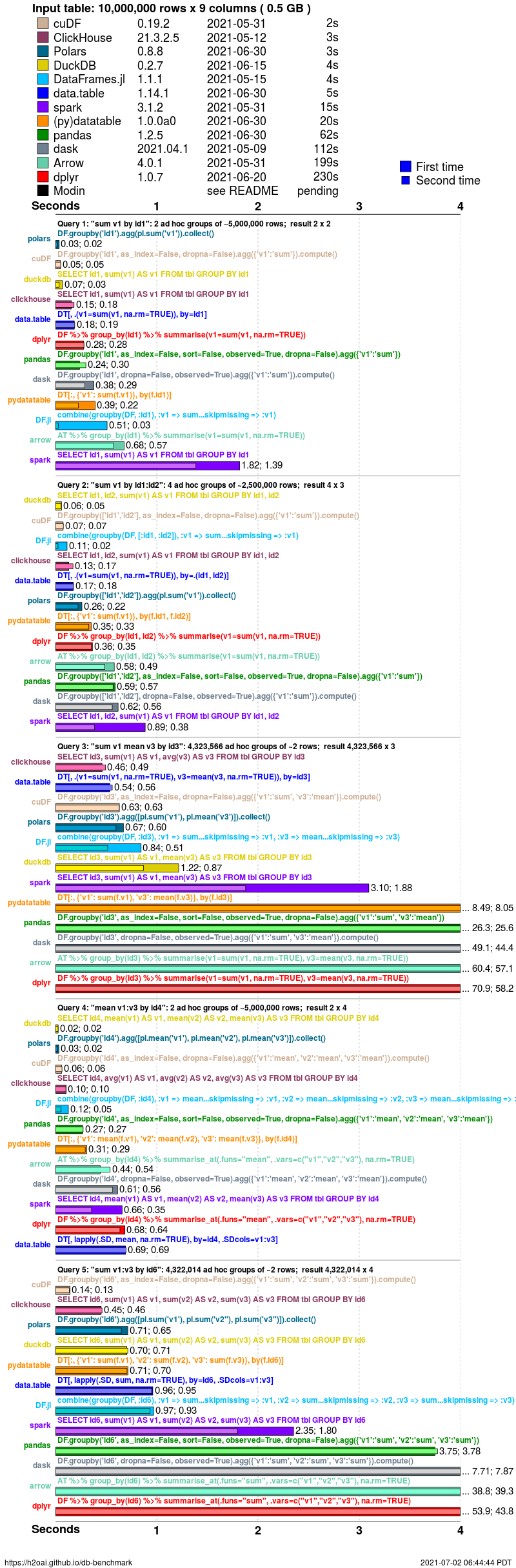
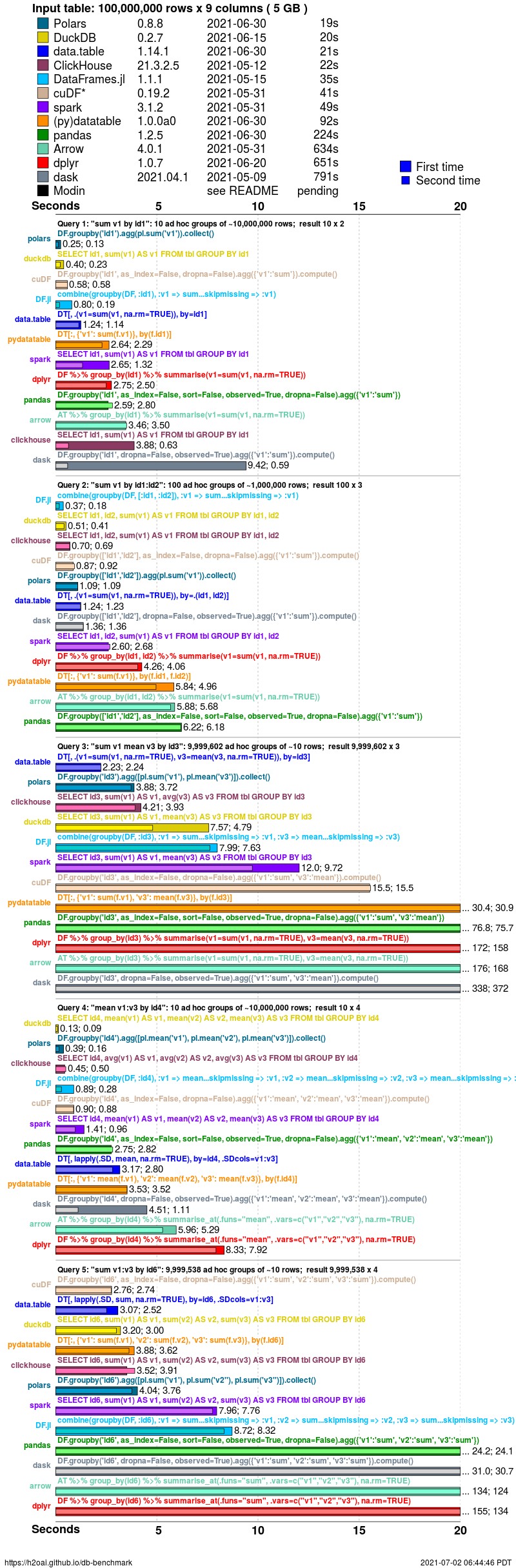
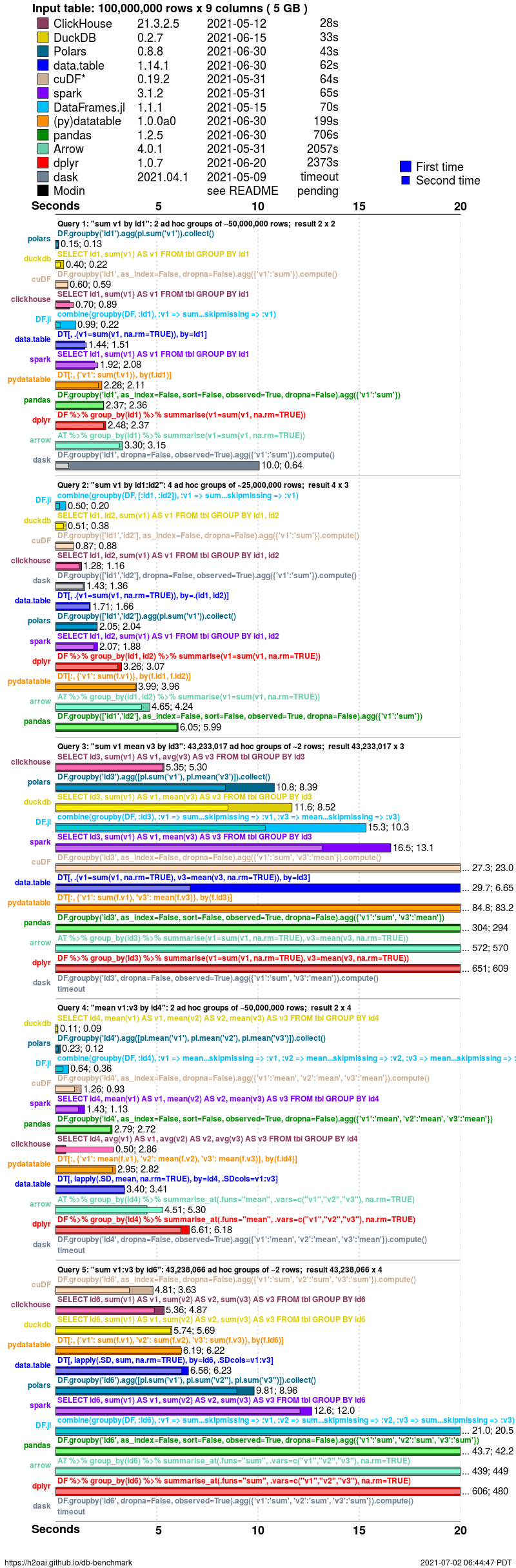
Timings are presented for a single dataset case having random order, no NAs (missing values) and particular cardinality factor (group size question 1 k=100). To see timings for other cases go to the very bottom of this page.
groupby timings
join
Timings are presented for datasets having random order, no NAs (missing values). Data size on tabs corresponds to the LHS dataset of join, while RHS datasets are of the following sizes: small (LHS/1e6), medium (LHS/1e3), big (LHS). Data case having NAs is testing NAs in LHS data only (having NAs on both sides of the join would result in many-to-many join on NA). Data case of sorted datasets tests data sorted by the join columns, in case of LHS these are all three columns id1, id2, id3 in that order.
join timings
groupby2014
This task reflects precisely grouping benchmark made by Matt Dowle in 2014 here. Differences are well summarized in the following post on Data Science stackexchange.
groupby2014 timings
Notes
- You are welcome to run this benchmark yourself! all scripts related to setting up environment, data and benchmark are in repository.
- Data used to generate benchmark plots on this website can be obtained from time.csv (together with logs.csv). See _report/report.R for quick introduction how to work with those.
- Solutions are using in-memory data storage to achieve best timing. In case a solution runs out of memory (we use 125 GB machine), it will use on-disk data storage if possible. In such a case solution name is denoted by a
*suffix on the legend. - For a cuDF solution on-disk memory actually means main memory because this is where memory spills from GPU memory.
- ClickHouse queries were made against
mergetreetable engine, see #91 for details. - ClickHouse and DuckDB queries are
CREATE TABLE ans AS SELECT ...to match the functionality provided by other solutions in terms of caching results of queries, see #151. - Arrow groupby task has been added but (as of Feb 2021) it is falling back to dplyr computation engine. Once native Arrow implementations will be ready, it will get automatically reflected thanks to automatic upgrades. For join task it is not yet implemented and also not falling back to dplyr either. For details see arrow#11679.
- We ensure that calculations are not deferred by solution.
- Because of the above, as of current moment, join timings of python datatable suffers from an extra deep copy. As a result of that extra overhead it suffers additionally with out of memory error for 1e9 join q5 big-to-big join.
- We also tested that answers produced from different solutions match each others, for details see _utils/answers-validation.R.
Environment configuration
- R 4.0.3
- python 3.6 and 3.7
- Julia 1.6.1
| Component | Value |
|---|---|
| CPU model | Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz |
| CPU cores | 40 |
| RAM model | DIMM Synchronous 2133 MHz |
| RAM GB | 125.78 |
| GPU model | GeForce GTX 1080 Ti |
| GPU num | 2 |
| GPU GB | 21.83 |
Scope
We limit the scope to what can be achieved on a single machine. Laptop size memory (8GB) and server size memory (250GB) are in scope. Out-of-memory using local disk such as NVMe is in scope. Multi-node systems such as Spark running in single machine mode is in scope, too. Machines are getting bigger: EC2 X1 has 2TB RAM and 1TB NVMe disk is under $300. If you can perform the task on a single machine, then perhaps you should. To our knowledge, nobody has yet compared this software in this way and published results too.
Why db-benchmark?
Because we have been asked many times to do so, the first task and initial motivation for this page, was to update the benchmark designed and run by Matt Dowle (creator of data.table) in 2014 here. The methodology and reproducible code can be obtained there. Exact code of this report and benchmark script can be found at h2oai/db-benchmark created by Jan Gorecki funded by H2O.ai. In case of questions/feedback, feel free to file an issue there.
Explore more data cases
| task | in rows | data description | benchplot |
|---|---|---|---|
| groupby | 1e7 | 1e2 cardinality factor, 0% NAs, unsorted data | basic, advanced |
| groupby | 1e7 | 1e1 cardinality factor, 0% NAs, unsorted data | basic, advanced |
| groupby | 1e7 | 2e0 cardinality factor, 0% NAs, unsorted data | basic, advanced |
| groupby | 1e7 | 1e2 cardinality factor, 0% NAs, pre-sorted data | basic, advanced |
| groupby | 1e7 | 1e2 cardinality factor, 5% NAs, unsorted data | basic, advanced |
| groupby | 1e8 | 1e2 cardinality factor, 0% NAs, unsorted data | basic, advanced |
| groupby | 1e8 | 1e1 cardinality factor, 0% NAs, unsorted data | basic, advanced |
| groupby | 1e8 | 2e0 cardinality factor, 0% NAs, unsorted data | basic, advanced |
| groupby | 1e8 | 1e2 cardinality factor, 0% NAs, pre-sorted data | basic, advanced |
| groupby | 1e8 | 1e2 cardinality factor, 5% NAs, unsorted data | basic, advanced |
| groupby | 1e9 | 1e2 cardinality factor, 0% NAs, unsorted data | basic, advanced |
| groupby | 1e9 | 1e1 cardinality factor, 0% NAs, unsorted data | basic, advanced |
| groupby | 1e9 | 2e0 cardinality factor, 0% NAs, unsorted data | basic, advanced |
| groupby | 1e9 | 1e2 cardinality factor, 0% NAs, pre-sorted data | basic, advanced |
| groupby | 1e9 | 1e2 cardinality factor, 5% NAs, unsorted data | basic, advanced |
| join | 1e7 | 0% NAs, unsorted data | basic |
| join | 1e7 | 5% NAs, unsorted data | basic |
| join | 1e7 | 0% NAs, pre-sorted data | basic |
| join | 1e8 | 0% NAs, unsorted data | basic |
| join | 1e8 | 5% NAs, unsorted data | basic |
| join | 1e8 | 0% NAs, pre-sorted data | basic |
| join | 1e9 | 0% NAs, unsorted data | basic |
| join | 1e9 | 5% NAs, unsorted data | basic |
| join | 1e9 | 0% NAs, pre-sorted data | basic |
| groupby2014 | 1e7 | 1e2 cardinality factor, 0% NAs, unsorted data | basic |
| groupby2014 | 1e8 | 1e2 cardinality factor, 0% NAs, unsorted data | basic |
| groupby2014 | 1e9 | 1e2 cardinality factor, 0% NAs, unsorted data | basic |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Benchmark run took around 163.3 hours.
Report was generated on: 2021-07-02 06:44:56 PDT.